
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2024年に公開された論文「Characterizing a Memory Allocator at Warehouse Scale」に基づいて、Googleが独自開発したLinuxのメモリ割り当てライブラリであるTCMallocの最適化に対する取り組みを紹介します。今回は、プロファイリングデータに基づいたTCMallocの最適化について説明します。
前回の記事の図3では、コンテナ内でスレッドが稼働するCPUコアの偏りから、Per-CPU Cahceの利用に偏りがあることを説明しました。Per-CPU Cacheで確保するメモリオブジェクトの量が均等な場合、メモリ割り当て要求が多いCPUコアでは、メモリオブジェクトの不足(キャッシュミス)に伴う処理遅延が発生する一方、メモリ割り当て要求が少ないCPUコアでは、未使用のメモリオブジェクトが多数存在してメモリフラグメンテーションが大きくなるという状況が発生します。
そこで、冒頭の論文では、キャッシュミスが多発するPer-CPU Cacheに対して、他のPer-CPU Cahceのメモリオブジェクトを再割り当てする仕組みを導入したことが説明されています。具体的には、Per-CPU Cacheごとにキャッシュミスの発生回数をカウントして、これを5秒ごとにチェックします。過去5秒間のキャッシュミスの回数がトップ5のPer-CPU Cacheに対して、他のPer-CPU Cahceからの再割り当てを行います。また、この仕組みがあれば、キャッシュミスが多発するPer-CPU Cacheは自動的にサイズが大きくなるので、デフォルトのサイズをこれまでよりも小さくすることができます。
これらの変更により、メモリフラグメンテーションが減少して、結果的に、データセンター全体でのメモリ使用量を減少することができます。図1は、実際の効果を示したもので、データセンター全体(fleet)で1.94%の削減を実現しています。その他のグラフは、特定のアプリケーションプロセスにおける削減量を示したものになります。
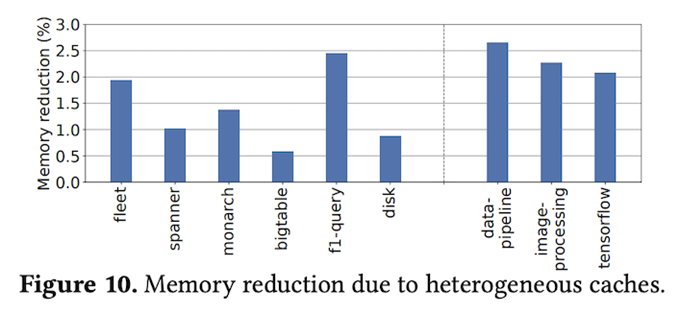
図1 Per-CPU Cacheの動的リサイジングの効果(論文より抜粋)
第186回の記事の図2にあるように、Per-CPU Cacheに割り当てられるメモリオブジェクトは、Central Free Listが管理するSpanから切り出されていきます。この結果、Span内に使用中のメモリオブジェクトと未使用のメモリオブジェクトが混在する「メモリフラグメンテーション」が発生します。一方、アプリケーションプロセスが使用中のメモリを解放すると、メモリオブジェクトは再びSpanに返却されていき、この解放プロセスが進んで、Span内のメモリオブジェクトがすべて解放されると該当のSpanはPageheapに返却されます。この時点で、該当Spanのメモリフラグメンテーションが解消されます。
そこで、Spanからメモリオブジェクトを取得する際に、「近々Pageheapに返却される可能性が高いSpan」の使用を避ける事で、メモリフラグメンテーションが解消される可能性を高める事ができます。一例として、機械学習を用いて、メモリフラグメンテーションが解消される確率を予測するという方法も考えられますが、冒頭の論文では、よりシンプルな実装例が紹介されています。具体的には、「未使用のメモリオブジェクトが多いSpanは、メモリフラグメンテーションが解消される確率が高い」という考え方です。図2は、これを実際に裏付けるデータで、Span内で使用中のメモリオブジェクト数が多くなるほど、Spanが返却される割合が下がることが分かります。
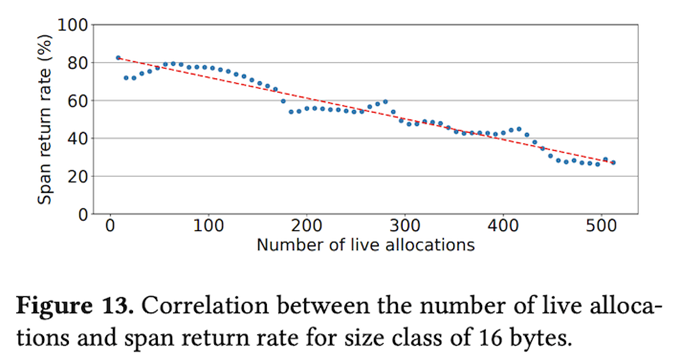
図2 使用中のメモリオブジェクト数とSpanの返却率の関係(論文より抜粋)
また、同様の議論は、Spanの返却先のPageheapでも成り立ちます。Pageheapは、HugepageからSpanを切り出して提供しますので、Hugepage内のSpanがすべた返却された時点で、Hugepageのメモリフラグメンテーションが解消します。そこで、Spanを管理するCentral Free Listと同様に、Hugepageを管理するPageheapにも、メモリフラグメンテーションが解消される可能性が低い部分を優先的に使用する仕組みを導入することができます。図3は、これらの効果を示すデータの1つで、データセンター全体(fleet)でメモリ使用量を1.41%削減することに成功しています。
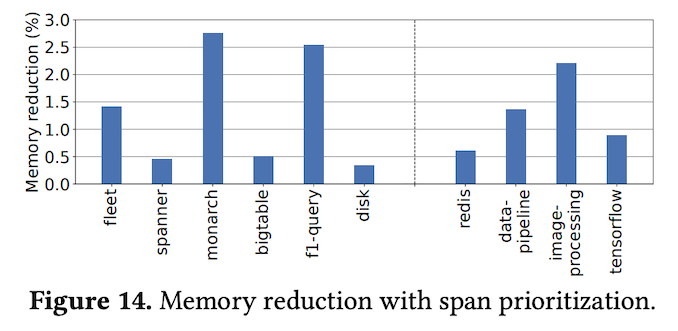
図3 メモリオブジェクトを割り当てるSpanの選択による効果(論文より抜粋)
論文内では、この他に、最近のCPUチップが採用する「NUCA(Non-Uniform Cache Accesses)」アーキテクチャーに対応した最適化も紹介されています。一般に、CPUチップにはメモリアクセスを高速化するキャッシュメモリが搭載されていますが、NUCAアーキテクチャーでは、CPUコアから最も遠い、最下層のキャッシュであるLLC(last-level cache)が複数のドメインに分かれており、該当ドメインに属するCPUコアからのアクセスが最も高速になるように設計されています。
先ほど、Per-CPU Cache間でメモリオブジェクトを移動するという説明がありましたが、NUCAアーキテクチャーのCPUでは、異なるドメインに属するCPUコアにメモリオブジェクトを移動すると、ドメインを跨いだLLCアクセスが発生してメモリアクセス性能が劣化する可能性があります。そこで、Per-CPU Cacheに対するメモリオブジェクトの割り当てを管理するTransfer Cacheの後段に、LLCのドメインごとに分かれた「NUCA-Aware Transfer Cache」を用意して、同じドメイン内でのメモリオブジェクトの再割り当てを優先的に行う仕組みが考えられます(図4)。論文内では、この仕組みを導入した結果、データセンター全体でアプリケーションのスループットが0.32%向上したことが報告されています。
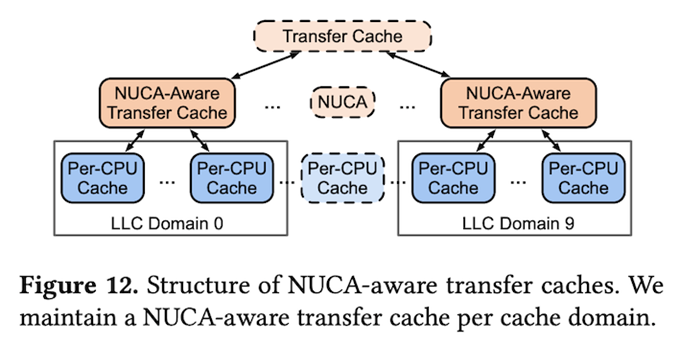
図4 LLCドメインごとにメモリオブジェクトを管理する仕組み(論文より抜粋)
今回は、2024年に公開された論文「Characterizing a Memory Allocator at Warehouse Scale」に基づいて、Googleが独自開発したLinuxのメモリ割り当てライブラリーであるTCMallocについて、プロファイリングデータに基づいたTCMallocの最適化について説明しました。
次回からは、ネットワークの構成管理に関する話題をお届けします。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































