
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2024年に公開された論文「Characterizing a Memory Allocator at Warehouse Scale」に基づいて、Googleが独自開発したLinuxのメモリ割り当てライブラリであるTCMallocの最適化に対する取り組みを紹介します。今回は、前回に続いて、TCMallocのプロファイリングデータを紹介します。
前回の記事では、TCMallocの基礎的なプロファイリングデータを紹介しました。今回は、メモリオブジェクトのサイズに関連したプロファイリングデータを追加で紹介します。まず、図1の「Object Count」(オレンジ色のグラフ)は、TCMallocが割り当てるメモリオブジェクトの数をメモリサイズごとに数えて累積分布として表したものです。これを見ると、1KB以下のメモリオブジェクトが全体の98%を占めていることが分かります。
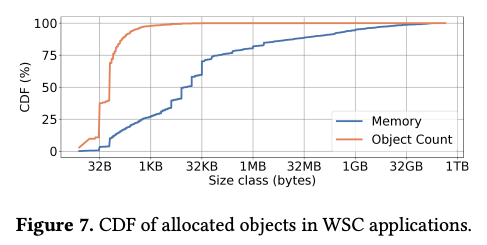
図1 メモリサイズごとのメモリオブジェクト数の累積分布(論文より抜粋)
したがって、TCMallocの性能を向上する上では、これらの小さなサイズのメモリオブジェクトを高速に割り当てることが重要になります。そこで、TCMallocでは、これまでに説明した階層構造による管理は256KB以下のメモリオブジェクトに限定して、それ以上のサイズはPageheapから直接に割り当てます。これは、階層構造によるメモリオブジェクトの管理は、Per-CPU Cacheから高速にメモリを割り当てられるメリットと同時に、各階層においてメモリフラグメンテーションが発生するというデメリットがあるためです。大きなサイズのメモリオブジェクトでフラグメンテーションが発生すると、より多くのメモリが無駄になります。256KBを超えるメモリを階層構造による管理から除外することは、高速なメモリ割り当てとメモリフラグメンテーションのメリット・デメリットのバランスを考えた仕組みと言えます。
なお、1KB以下のメモリオブジェクトは「個数」では全体の98%を占めますが、個々のサイズが小さいため、実際に使用するメモリはそれほど大きくはなりません。図1の「Memory」(青色のグラフ)は、それぞれのサイズのメモリオブジェクト群が実際に確保したメモリ容量の累積分布を表します。これによると、1KB以下のメモリオブジェクトが使用するメモリ容量は全体の28%になります。
そして、次の図2(左図)は、個々のメモリオブジェクトがアプリケーションプロセスに割り当てられてから返却されるまでの時間(ライフタイム)をヒートマップで示したものです。横軸がメモリオブジェクトのサイズで縦軸がライフタイムに対応します。
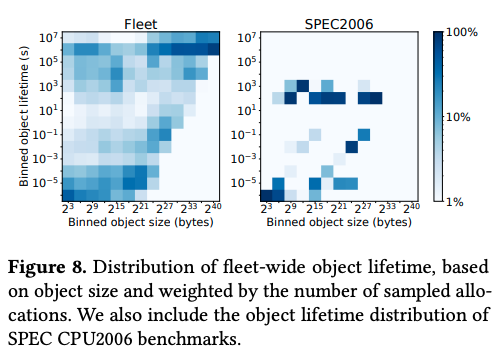
図2 メモリオブジェクトのサイズと使用時間の分布(論文より抜粋)
この結果から、2^24(16MB)以下のメモリオブジェクトは、1ミリ秒以下から1週間以上に渡る、広範囲のライフタイムを持つ事が分かります。一方、それより大きなサイズのメモリオブジェクトは、ライフタイムが長くなる傾向があり、1GB以上のメモリオブジェクトの65%は、1日以上のライフタイムを持ちます。なお、図2の右図は、SPEC2006ベンチマークを実行した場合の同様の分布を表します。前回の記事の図2と同様に、ベンチマークツールのメモリ使用パターンは、実際のアプリケーションプロセスとは大きく異なることが分かります。
これまでに説明したように、TCMallocは、Per-CPU CacheによってメモリオブジェクトのプールをCPUコアごとに分ける事で、スレッド間の排他処理を不要にして、高速なメモリオブジェクトの割り当てを実現しています。この時、CPUコアによって、TCMallocの呼び出し数に偏りが発生することはないのでしょうか? 仮にそのような偏りがあれば、呼び出しが多いCPUコアのPer-CPU Cacheにより多くのメモリオブジェクトを割り当てる事で、最適化を図る事ができそうです。
特に、Googleのデータセンターでは、アプリケーションプロセスは、Borgによって管理されるコンテナ環境で稼働しており、1つのコンテナに割り当てられた複数のCPUコアは、基本的には、1つのアプリケーションプロセスのみが使用します。従って、該当プロセスのスレッド数がコンテナに割り当てられたCPUコア数より少なければ、スレッドが稼働しない(すなわち、TCMallocを呼び出す事がない)CPUコアが常に存在することになります。この状況を実際に示すのが、図3のデータです。
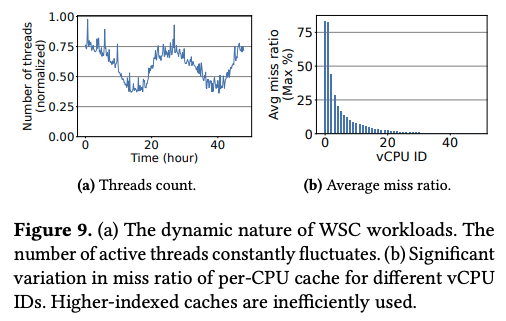
図3 Per-CPU Cacheの利用の偏り示すデータ(論文より抜粋)
まず、図3の左図は、Google検索サービスの一部を構成するワーカーノードのスレッド数の変化を示したものです。サービスのピーク時間に応じてスレッド数が変化しており、言い換えると、TCMallocを使用するCPUコアは時間的に変動することが分かります。そして、図3の右図は、CPUコアごとのキャッシュミス(TCMallocにメモリ割り当てを要求した際に、対応するPer-CPU Cacheに未使用のメモリオブジェクトが存在しない状況)の発生率を示したものです。コンテナに割り当てられたCPUコアには、0から始まるvCPU IDが振られており、コンテナ内のスレッドは、vCPU IDの順番にCPUコアを使用します。そのため、vCPU IDが小さいCPUコアほどスレッドが稼働する時間が長く、キャッシュミスも多く発生しています。これは、vCPU IDが小さなCPUコアに対応するPer-CPU Cacheが、より頻繁に利用されることを表します。
今回は、前回に続いて、2024年に公開された論文「Characterizing a Memory Allocator at Warehouse Scale」に基づいて、Googleが独自開発したLinuxのメモリ割り当てライブラリーであるTCMallocのプロファイリングデータを紹介しました。次回は、これらのデータを元にしたTCMallocの最適化について説明します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































