
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2024年に公開された論文「Characterizing a Memory Allocator at Warehouse Scale」に基づいて、Googleが独自開発したLinuxのメモリ割り当てライブラリであるTCMallocの最適化に対する取り組みを紹介していきます。今回は、TCMallocのアーキテクチャーの概要を説明します。
Linux上のアプリケーションプロセスが稼働中に必要なメモリを確保する際は、C言語であればmallocなど、各言語に標準のライブラリ関数を用います。これらのライブラリ関数は、mmapシステムコールを利用してLinuxカーネルから(ページと呼ばれる単位の)一定サイズのメモリを取得した後、これを分割して受け渡します。このようなメモリ割り当て処理は、データセンターで稼働する多数のアプリケーションが共通に利用するため、このライブラリ関数を最適化する事は、データセンター全体の最適化に貢献することになります。
そこで、Googleでは、mallocに代わる独自のメモリ割り当てライブラリであるTCMallocを開発・使用しており、そのソースコードは、オープンソースとしてGitHubのリポジトリで公開されています。TCMallocは、C言語、および、C++で使用できます。そして、冒頭の論文では、Googleのデータセンターで稼働する代表的なアプリケーションに対するTCMallocのプロファイリングデータと共に、Googleのデータセンターの特性に対応した最適化が紹介されています。
ここではまず、冒頭の論文に従って、TCMallocのアーキテクチャーの概要を説明します。TCMallocは、通常のmallocと同様に、mmapシステムコールを用いてLinuxカーネルから一定サイズ(Hugepageサイズ)のメモリページを取得します。ここから、Spanと呼ばれる一定サイズのブロックを切り出した後、Span内に複数のメモリオブジェクトを用意します。メモリオブジェクトのサイズは、事前に定義された複数のサイズクラスに分かれており、1つのSpanには、同一サイズのメモリオブジェクトが格納されます。論文では、256KB以下の小さなサイズのメモリオブジェクトでは、80~90種類程度のサイズクラスがあると説明されています。図1は、これらの関係を表した図になります。
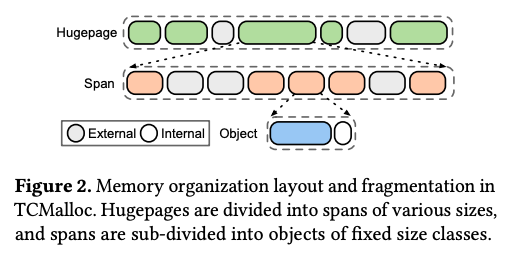
図1 TCMallocによるメモリ分割処理(論文より抜粋)
アプリケーションが(TCMallocが提供する)malloc関数でTCMallocにメモリ割り当てを要求すると、要求量を満たす最小サイズのメモリオブジェクトが割り当てられます。図1の「Internal」で示された部分は、アプリケーションが要求したサイズと実際に割り当てられたメモリオブジェクトのサイズの差分に当たる部分で、これは実際には使用されないオーバーヘッドになります。また、アプリケーションが割り当てられたメモリを解放すると、該当のメモリオブジェクトは未使用状態になります。図の「External」で示された部分は、このような未使用状態の部分を表しますが、同じサーバー上の他のアプリケーションからは利用できないので、これもまた一種のオーバーヘッドと言えます。(TCMallocのバイナリコードは、該当のアプリケーションの一部としてリンクされており、TCMallocが確保したメモリページは、該当のアプリケーションプロセスが確保した状態になる点に注意してください。)
したがって、アプリケーションプロセス内の多数のスレッドがそれぞれにメモリの要求と解放を繰り返すと、このような未使用部分が点在する、いわゆる「メモリフラグメンテーション」が発生します。メモリフラグメンテーションの発生を低減することは、TCMalloc最適化の目標の1つになります。
そして、TCMallocは、図2のような仕組みで、図1の階層的なメモリ管理を実現します。
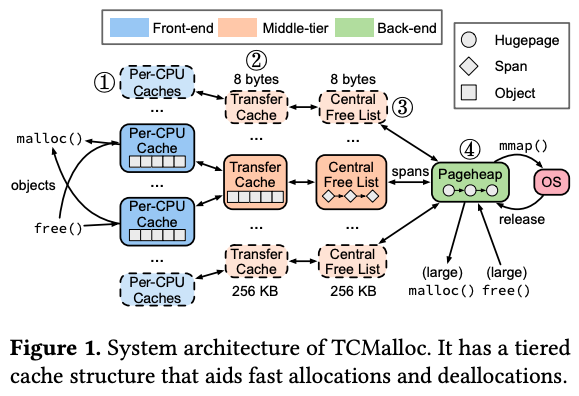
図2 TCMallocのアーキテクチャー(論文より抜粋)
図2の④の「Pageheap」は、mmapシステムコールで取得したメモリページへのポインタを保存した連結リストです。そして、③の「Central Free List」は、各メモリページ内のSpanへのポインタを保存した連結リストです。1つのSpanには同一サイズのメモリオブジェクトが格納されるので、メモリオブジェクトのサイズごとにSpanが分かれることになり、Spanへのポインタを管理するCentral Free Listは、メモリオブジェクトのサイズごとに用意されます。そして、②の「Transfer Cache」には、Span内のメモリオブジェクトへのポインタが格納されます。そしてさらに、それぞれのメモリオブジェクトは、CPUコアごとに振り分けられます。①の「Per-CPU Cache」は、CPUコアごとに割り当てられたメモリオブジェクトへのポインタが格納されます。
アプリケーションプロセス内のスレッドがmalloc関数を呼び出すと、該当のスレッドが稼働するCPUコアのPer-CPU Cacheからメモリオブジェクトが割り当てられます。異なるCPUコアで稼働する複数のスレッドが同時にメモリ割り当てを要求しても、それぞれに異なるPer-CPU Cacheが用いられるので、スレッドの競合を心配する必要がなく、スレッド間のロック管理のオーバーヘッドが削減できます。
また、図2の各階層に割り当てられるメモリは、動的に変化します。例えば、Per-CPU Cache内のメモリオブジェクトがすべてアプリケーションプロセスに割り当てられると、新しいメモリオブジェクトがTransfer Cacheから割り当てられます。同様に、Transfer Chace内のメモリオブジェクトが不足すると、Central Free Listから割り当てられます。これとは逆に、Per-CPU Cache内で、プロセスから解放されたメモリオブジェクトが増加すると、これらはTransfer Cacheに返却されます。この解放プロセスが進んで、Span内のメモリオブジェクトがすべて解放されると、該当のSpanはPageheapに返却されます。
仮に、Span内のメモリオブジェクトが同じタイミングで解放されれば、前述のメモリフラグメンテーションが低減できることになります。冒頭の論文では、この点を意識したTCMallocの最適化についても説明されています。
今回は、2024年に公開された論文「Characterizing a Memory Allocator at Warehouse Scale」に基づいて、Googleが独自開発したLinuxのメモリ割り当てライブラリーであるTCMallocのアーキテクチャーの概要を説明しました。冒頭の論文では、TCMallocのプロファイリングデータを元に実施したTCMallocの最適化が解説されていますが、次回は、この最適化の元になるプロファイリングデータを紹介したいと思います。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































