
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2023年に公開された論文「CAPA: An Architecture For Operating Cluster Networks With High Availability」に基づいて、データセンターネットワークの構成変更を安全に実行するためにGoogleのエンジニアが開発した、CAPA(containment and prevention architecture)と呼ばれるアーキテクチャーを紹介していきます。今回は、CAPAが大規模な障害を防止した具体例を紹介します。
前回の記事では、CAPAによる構成変更の例を紹介しましたが、その中では、レギュレーションレイヤーが同時に行われる構成変更の数を制限するなどの処理を行いました。Googleでは、ネットワーク全体の構成をMALT(Multi-Abstraction-Layer Topology representation)と呼ばれる独自の構成言語で記述しており、CAPAでは、この構成情報を元にして許可される操作を定義します。たとえば、「グローバルネットワーク全体で最大N個のクラスターネットワークの同時変更を許可する」「1つのクラスターネットワークでは、4つのSDNコントローラーに大して15分の間隔を空けて順番に変更する」などの定義ができます。特に、4つのSDNコントローラーを順番に処理することで、クラスターネットワークの構成変更に伴う一時的なキャパシティの減少は、最大でも25%に抑えられます。
また、ベストプラクティスの1つとして、障害ドメインの分離がありました。論文内では、この例として、図1のクラスターネットワークの構成が挙げられています。クラスターの構成を管理する管理サーバー(NCS:Network control server)は、クラスターごとに用意するなど、1つのクラスターは必ずそれだけで独立したシステムになっており、クラスター外部のコンポーネントに依存しない形になっています。オレンジ色の波線で示された「Low-dep Boundary」がこのクラスターの障害ドメインの境界にあたります。
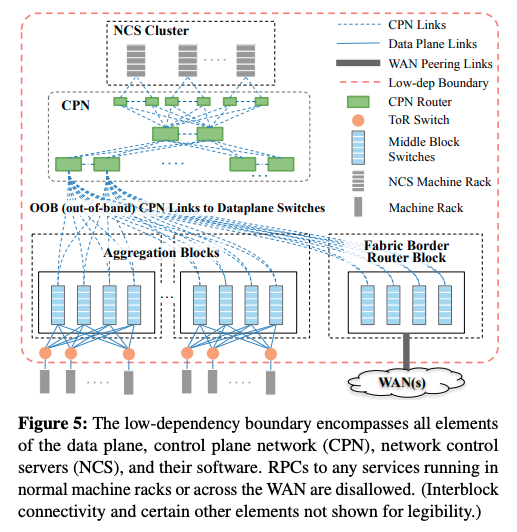
図1 クラスターネットワークの構成(論文より抜粋)
ただし、WANとの接続部分だけは、障害ドメイン分離の例外になります。各クラスターのFBR(Fabric Border Router)は、BGPのプロトコルで他のクラスターと経路情報を交換しており、BGPの動作に問題が発生すると、その影響は複数のクラスターに伝搬してしまいます。そのため、それぞれのFBRには、BGPに依存しない静的経路があらかじめ定義されており、万一、BGPが利用できなくなった場合は、事前定義された静的経路を使用します。この静的経路は、通信経路としては最適化されたものではありませんが、BGPの障害に起因するグローバルなネットワーク障害を防ぐ効果が期待できます。
論文内では、CAPAが大規模な障害の発生防止に役立ったいくつかの例が紹介されています。ここでは、その中から2つの例を説明します。
1つ目は、ネットワークモデルの不整合に起因する障害です。前述のように、Googleでは、MALTと呼ばれる構成言語でネットワークの構成を記述しており、「本来あるべき構成状態」を宣言すると、ネットワーク構成管理システムは、実際のネットワーク構成と比較して、宣言と異なる部分を自動的に修正します。ある時、ネットワーク構成のモデリングシステムにバグが混入して、誤った構成状態が「本来あるべき構成状態」として定義されました。ネットワーク構成管理システムは、この誤った情報に基づいて、グローバルネットワーク全体の構成を大きく変更する大量の変更処理をCAPAに要求しました。この時、CAPAは、変更処理の同時実行数に制限をかけると同時に、大量の変更処理がブロック状態にあることを検知して、アラートを発生したため、障害が発生する前にこれらの変更を中止できたそうです。特に、変更によって影響を受けるリンクを通過するパケットを排除するドレイン処理が行われない限り、該当のリンクに影響を与える変更はブロックされるようになっており、エンドユーザーに影響を及ぼすことはありませんでした。
2つ目は、ネットワークスイッチのソフトウェアアップデートの失敗に起因する障害です。ここでは、多数のネットワークスイッチに対して、構成ファイルのフォーマットを変更するアップデートを行なった後、該当の構成ファイルを前提としたソフトウェアのアップデートを配信するという作業が行われました。この際、修理中で停止しているスイッチの情報を保存したデータベースに問題があり、構成ファイルの変更処理を行う際に、多数のスイッチが誤って修理中とみなされてしまい、構成ファイルが更新されませんでした。その後、ソフトウェアのアップデートの配信が開始すると、構成ファイルが未更新のスイッチでは新しいバージョンのソフトウェアが正しく動作せず、不安定な状態に陥りました。この配信処理はCAPAによって行われていたので、CAPAはスイッチの問題に伴うキャパシティの減少を検知して、それ以上のアップデートの配信処理をブロックしました。
これらの例から、CAPAを介して変更処理を行うことにより、上流のワークフローレイヤーが不正な変更を行おうとしても、ネットワークを不安定にする変更はレギュレーションレイヤーによって事前にブロックされることが分かります。論文内では、CAPAを導入した後の5年間に渡る(CAPAによって防止できたものを含めた)障害事例を分析した結果、「CAPAを導入していなかったと仮定した際に発生した障害」の84%がCAPAによって防止できたことが示されています。
今回は、2023年に公開された論文「CAPA: An Architecture For Operating Cluster Networks With High Availability」に基づいて、データセンターネットワークの構成変更を安全に実行するためにGoogleのエンジニアが開発したアーキテクチャーCAPAについて、CAPAが大規模な障害を防止した具体例を紹介しました。
次回は、サーバーシステムのメモリーアーキテクチャーに関する話題をお届けします。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes

























