
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2023年に公開された論文「CAPA: An Architecture For Operating Cluster Networks With High Availability」に基づいて、データセンターネットワークの構成変更を安全に実行するためにGoogleのエンジニアが開発した、CAPA(containment and prevention architecture)と呼ばれるアーキテクチャーを紹介していきます。今回は、CAPAによる処理の流れを具体例で説明します。
前回の記事で説明したように、CAPAの目的は、個々のネットワーク管理者やソフトウェアエンジニアに依存することなく、ベストプラクティスに従った安全な構成変更を実現することです。冒頭の論文では、CAPAの設計で考慮したベストプラクティスの主要項目として、次の5つをあげています。
CAPAを利用することで、これらのベストプラクティスがどのように適用されるかを理解するために、CAPAによる構成変更の具体例を見てみます。この後の説明を読む前に、前回の記事の図1で説明した、「Operations Workflows(ワークフローレイヤー)」→「Regulation Systems(レギュレーションレイヤー)」→「Production Critical Systems」の流れを再確認しておいてください。
ここでは、ネットワークのキャパシティを拡張する例で説明します。はじめに、ワークフローレイヤーに実装されたトラフィック予想システムが、クラスターネットワークと外部ネットワークを相互接続するFBR(Fabric Border Router)のリンク部分でキャパシティ不足が発生すると予測したとします。このシステムは、追加が必要な光ケーブルやトランシーバーの個数を計算して、発注管理システムに発注のリクエストを送信します。発注したパーツがデータセンターに到着すると、データセンターの作業員に指示を出して、これらのパーツを追加接続します。
続いて、追加されたリンクを使用するようにネットワークの構成変更を行います。第105回の記事(Googleの新しい分散型SDNコントローラー「Orion」(パート2))の図2にあるように、Googleのクラスターネットワークは、耐障害性を高めるために4つのSDNコントローラーによって管理されており、それぞれのコントローラーは独立したネットワーク経路(リンク)を管理します。そこで、ワークフローレイヤーの構成変更システムは、それぞれのコントローラーが管理する経路を順番に変更していきます。つまり、どれか1つのコントローラーの変更に失敗しても、残り3つのコントローラーが管理する経路には影響を与えません。この後の説明は、特定の1つのコントローラーに対する処理と考えてください。
ワークフローレイヤーの構成変更システムは、まずは、変更によって影響を受けるリンクを通過するパケットを排除するドレイン処理を行います。ただし、この部分はレギュレーションレイヤーを介して実行するので、構成変更システムは、レギュレーションレイヤーのDrain APIにドレイン処理を依頼します。すると、レギュレーションレイヤーは、リクエスト元のワークフローがこの処理を行う権限を持っていることを確認した上で、さらに、この処理でキャパシティが減少した際に、事前に定義されたキャパシティの最低量を下回らないことを確認します。
この時、他の構成変更が同時に行われており、すでにキャパシティが減少していると、このドレイン処理を同時に行うと、キャパシティの最低量を下回る可能性があります。このような場合は、他の処理が終了して必要なキャパシティが回復するまでドレイン処理の実行をブロックします。図1は、このような状況を図示したもので、処理1(Op1)と処理2(Op2)の実行中に、処理3(Op3)の実行依頼が来たものの、キャパシティの最低量に達しているため、処理2が終了するまで、処理3の開始がブロックされています。
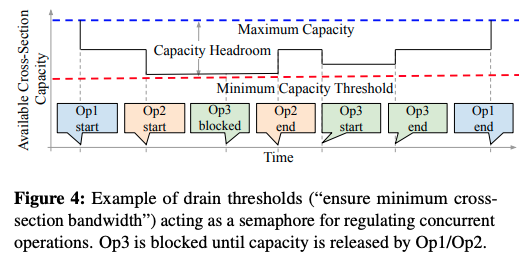
図1 3種類の変更処理が同時に進行する例(論文より抜粋)
Drain APIの処理が完了すると、続いて、ワークフローレイヤーの構成変更システムは、レギュレーションレイヤーのConfig APIに必要な構成変更の処理を依頼します。これが完了すると、最後にUndrain APIを用いて、構成変更後のリンクの利用を開始します。それぞれのAPIは、担当する変更処理を実行している間、システムの健全性を示すメトリック(ブラックボックス型のメトリック、および、ホワイトボックス型のメトリック)をモニタリングしており、何らかの異常を検知すると、変更開始前の状態にロールバックします。つまり、これらのAPIの処理はアトミックに実装されており、APIの処理が終了した段階で、変更対象のシステムは、変更が完了した状態、もしくは、変更開始前の状態のどちらかになっています。この例では、Drain API、Config API、Undrain APIの3種類のAPIを使用しましたが、この他にも、図2のようなAPIが提供されています。
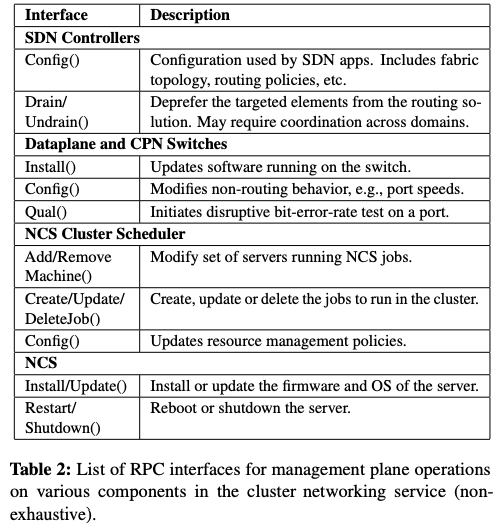
図2 レギュレーションレイヤーが提供するAPIの例(論文より抜粋)
このように、実際の構成変更を行う部分をレギュレーションレイヤーに依頼することで、必要なキャパシティの確保や問題発生時のロールバックなど、ベストプラクティスとして考えるべき処理が自動的に行われます。ワークフローレイヤーを実装するエンジニアは、レギュレーションレイヤーのAPIを利用することで、これらの処理を自分で考える必要がなくなります。
今回は、2023年に公開された論文「CAPA: An Architecture For Operating Cluster Networks With High Availability」に基づいて、データセンターネットワークの構成変更を安全に実行するためにGoogleのエンジニアが開発したアーキテクチャーCAPAについて、CAPAによる処理の流れを具体例で説明しました。次回は、CAPAが大規模な障害を防止した具体例を紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes

























