
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2024年に公開された論文「Characterizing a Memory Allocator at Warehouse Scale」に基づいて、Googleが独自開発したLinuxのメモリ割り当てライブラリであるTCMallocの最適化に対する取り組みを紹介します。今回は、TCMallocのプロファイリングデータを紹介します。
前回の記事では、TCMallocはデータセンターで稼働する多くのアプリケーションが利用するため、TCMallocの最適化は、データセンター全体の最適化に貢献すると説明しました。これは、見方を変えると、特定のアプリケーションに特化した最適化には意味がないことにもなります。この状況を示すのが、次の図1のデータです。
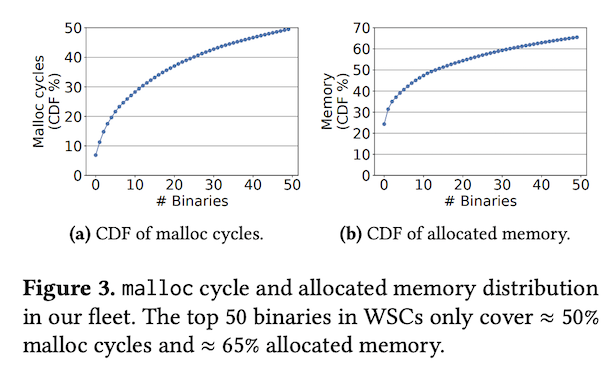
図1 アプリケーションごとのTCMalloc使用頻度の累積分布(論文より抜粋)
左の図は、Googleのデータセンターで稼働するアプリケーションをTCMallocの処理時間(CPUサイクル)が多い順に並べて、これらの累積分布を示したものです。50種類のアプリケーションによる処理時間を累積しても、TCMallocの処理時間全体の50%にしかなっておらず、多数のアプリケーションが均等にTCMallocを使用していることが分かります。右の図は、TCMallocによって割り当てられたメモリー量について、同様の累積分布を示したものです。
また、論文内では、TCMallocの使用頻度が高い上位5つのアプリケーションプロセスとして、以下が挙げられています。いずれも分散データ処理に関連したアプリケーションで、データをキャッシュするためにメモリを多用していると想像されます。
次の図2は、アプリケーション実行時のTCMallocのオーバーヘッドを上記の5つのアプリケーションプロセス、および、データセンター全体での平均(fleet)について示します。
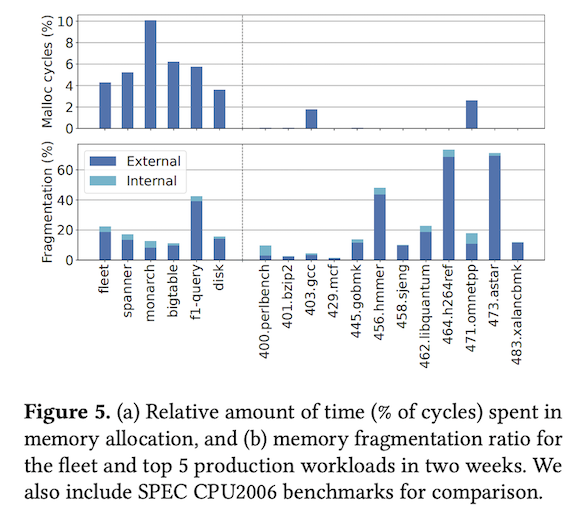
図2 TCMallocのオーバーヘッド(論文より抜粋)
図2の上図は、アプリケーションプロセスのCPU使用時間全体における、TCMallocによる使用時間の割合を示します。平均で4.6%、トップ5のアプリケーションで3.6%~10.1%になっており、TCMallocによる処理時間がそれなりの割合を占めていることが分かります。言い換えれば、TCMallocを最適化して、TCMallocによる処理時間を低減すれば、データセンター全体でCPU使用時間を削減できることになります。また、図2の下図は、メモリフラグメンテーションの発生割合(TCMallocが確保したメモリ容量の中でアプリケーションプロセスが使用していない割合)を示します。こちらも同様に、それなりの割合の未使用領域が発生しており、メモリフラグメンテーションの発生を低減することで、無駄なメモリ使用量を削減できることがわかります。
図2の右側にある「400.perfbench」などのグラフは、参考として、一般的なベンチマークツールを実行した際のデータを表します。これらのベンチマークツールは実行中の動的なメモリ確保を避けるように実装されているようで、TCMallocの使用時間がほとんど発生していません。つまり、これらのツールは、データセンターで稼働する実際のアプリケーションプロセスとはメモリ取得に関する挙動が異なっており、TCMallocを最適化する際の指標には適しません。ベンチマークツールに特化した最適化ではなく、現実のワークロードに対して最適化することの重要性が分かります。
前回の記事の図2に示したように、TCMallocによるメモリオブジェクトの管理は階層構造を持っており、アプリケーションプロセスがメモリオブジェクトを取得する際は、どの階層まで処理が必要になるかで処理時間が変わります。Per-CPU Cacheから直接取得できる場合が最も早く、その前段のCacheからの再確保が必要になるとより多くの時間がかかると想像できます。これを実際に示すのが図3のデータです。
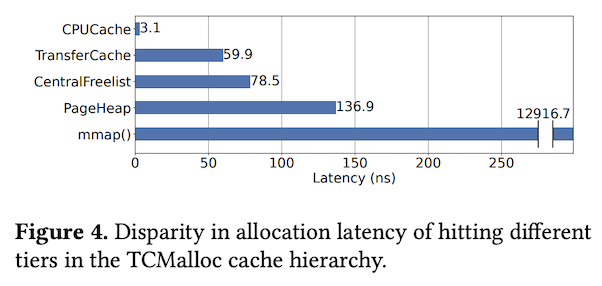
図3 メモリオブジェクトを取得する階層による性能の違い(論文より抜粋)
Per-CPU Cacheからの取得が圧倒的に高速ですが、これには2つの理由があります。1つは、この部分の処理は、最小のCPUインストラクションで処理が完結するように、アセンブリ言語を用いてコーディングされていることです。そして、もう一つは、CPUコアごとにキャッシュが用意されているので、スレッド間のロック処理が不要なことです。Transfer Cacheより前段のキャッシュは複数のCPUコアから共有されているため、この部分を利用する際は、複数スレッドの同時アクセスを避けるためのロック処理が必要になります。このように、未使用のメモリオブジェクトをPer-CPU Cacheに事前に割り当てる事で、メモリ取得を高速に行う点がTCMallocの特徴になります。
そして、次の図4の上図は、前述の5つのアプリケーションプロセス、および、データセンター全体(fleet)について、TCMallocの処理時間の内訳を示します。ここまでの説明から分かるように、CPUCacheの割合が多いほど、より高速に処理できることになります。
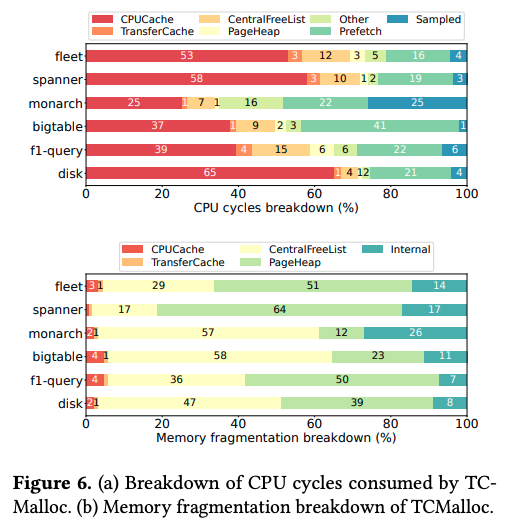
図4 CPU使用時間とメモリフラグメンテーションの内訳(論文より抜粋)
また、メモリフラグメンテーションについても同様に、Cacheの階層構造のどの部分でフラグメンテーションが発生するかを考える必要があります。図4の下図はこれを示したもので、フラグメンテーションの多くは、CentralFreeListとPageHeapで発生していることが分かります。CentralFreeListは複数のメモリオブジェクトを含むSpanを管理する部分ですので、Span内のメモリオブジェクトの大部分が未使用で、一部だけが長時間使用されている状況が続くと、この部分のフラグメンテーションの割合が大きくなります。
論文内では、この他にもいくつかのプロファイルデータが紹介されており、これらのデータを元にしてTCMallocの最適化が行われます。追加のプロファイルデータ、および、最適化の内容については次回以降にあらためて説明します。
今回は、2024年に公開された論文「Characterizing a Memory Allocator at Warehouse Scale」に基づいて、Googleが独自開発したLinuxのメモリ割り当てライブラリーであるTCMallocについて、代表的なプロファイリングデータを紹介しました。次回は、この他の特徴的なプロファイリングデータを続けて紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































