
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2024年に公開された論文「BigLake: BigQuery’s Evolution toward a Multi-Cloud Lakehouse 」に基づいて、マルチクラウド対応に向けたBigQueryの機能拡張について解説します。今回は、オブジェクトストレージにデータを保存するBigLake Tablesのアーキテクチャーを紹介します。
前回の記事の図2に示したように、BigQueryは、データの保存場所として、BigQuery標準のストレージ(BigQuery Storage)に加えて、Google Cloud Storageや他のクラウド上のオブジェクトストレージを用いることができます。これらのオブジェクトストレージにデータを保存する際に使用するのがBigLake Tablesです。そして、第176回からの記事「Vortex: BigQueryのStorage APIを支えるStorageエンジン」で解説したように、BigQueryに対するデータの読み書きは、BigQueryが提供するStorage APIを介して行われます。この点は、BigLake Tablesについても変わりありません。BigQueryを利用するユーザー、および、外部アプケーションに対して、BigQuery標準のManaged Tablesと同等の機能が提供されます。
BigQueryのテーブルは、カラムレベル、行レベルでのアクセス制御が行われますが、この点も変わりありません。Storage APIを介してテーブルにアクセスすることにより、データの保存場所に関わらず、一貫したセキュリティポリシーが適用されます。BigLake Tablesの場合、内部的には、ユーザーごとに対応するアクセス権が定義された「Connection object」が各テーブルに用意されており、ユーザーがQueryを実行すると、該当ユーザーのConnection objectを用いて、オブジェクトストレージに対するアクセスが行われます。
第178回の記事で触れたように、BigQueryでは、Big Metadataと呼ばれる専用のメタデータ管理システムで各テーブルのメタデータを管理しています。BigLake Tablesの場合も同じメタデータ管理システムを使用することで、クエリーの性能を向上しています。BigLake Tablesでは、ParquetやIcebergなどのオープンなデータフォーマットを用いたテーブルを使用しますが、通常、これらのフォーマットが提供するメタデータはストレージ上のファイル自身に保存されるため、メタデータの読み取りに時間がかかります。そこで、BigLake Tablesでは、ファイル内のメタデータ、および、その他の統計情報をBig Metadataをバックエンドとするメタデータキャッシュに保存します(図1)。
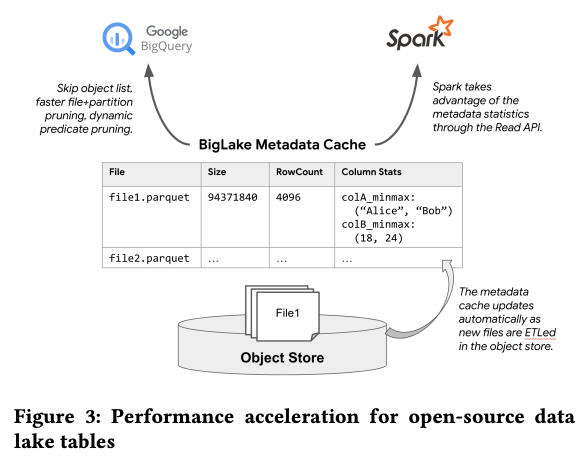
図1 メタデータキャッシュによる性能向上の仕組み(論文より抜粋)
メタデータキャッシュに保存された情報を利用することで、クエリープランの最適化を行ったり、データアクセスの際に必要なファイルの必要な箇所にダイレクトにアクセスすることが可能になります。メタデータキャッシュの効果により、「TPC-DS 10T」ベンチマークにおいて、4倍程度の高速化が実現されることが論文内で報告されています。
前述のように、BigLake Tablesは、メタデータキャッシュによってクエリーの性能向上を図っていますが、書き込み処理については、オブジェクトストレージをバックエンドとすることによるボトルネックがまだ残ります。テーブルに書き込まれたデータは、追記型のトランザクションログファイルに書き込まれた後、定期的に読み取りに最適化されたフォーマットに変換されます。この際、一般的なオブジェクトストレージは、1秒あたりの書き込み回数の上限が小さいため、この点がトランザクションログファイルの書き込みに対するボトルネックになります。
この課題を解決するのが、BigLake Managed Tables(BLMT)です。BLMTは、BigLakeのバックエンドストレージとして、Google Cloud Storageを使用する際に利用できます。BLMTは書き込み処理に使用するトランザクションログを前述のBigMetadataに保存するので、オブジェクトストレージの書き込み回数の上限によるボトルネックがありません。また、一般のBigLake TablesよりもBigQueryとのインテグレーションが強化されており、複数テーブルにまたがったトランザクションなど、一般のBigLake Tablesではサポートされない機能を使用することもできます。
BLMTのデータは、オブジェクトストレージ上では、Parquet形式になっていますが、メタデータ部分はBigMetadataで管理されているので、Parquet形式のデータファイルとして直接にアクセスすることはできません。外部アプリケーションからデータファイルに直接アクセスしたい場合は、メタデータ部分をIcebergスナップショットとしてエキスポートして利用します(図2)。
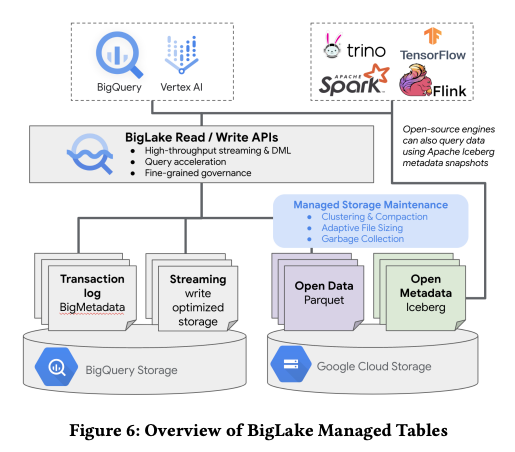
図2 BigLake Managed Tablesのアーキテクチャー(論文より抜粋)
今回は、2024年に公開された論文「BigLake: BigQuery’s Evolution toward a Multi-Cloud Lakehouse」に基づいて、オブジェクトストレージにデータを保存するBigLake Tablesのアーキテクチャーを紹介しました。次回は、マルチクラウドに対応したLakehouseとしての機能を提供するBigQuery Omniのアーキテクチャーを紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes

























