
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2024年に公開された論文「Vortex: A Stream-oriented Storage Engine For Big Data Analytics」に基づいて、BigQueryのStorage APIを支えるストレージエンジンであるVortexのアーキテクチャーを解説していきます。今回は、Vortexのアーキテクチャーの概要とVortexの特徴を紹介します。
BigQueryは、Google Cloudが提供する分散型のデータウェアハウスで、図1に示すようにデータを保存するストレージ部分(ストレージエンジン)とクエリーを実行する計算リソース(クエリーエンジン)が分離したアーキテクチャーを持ちます。ストレージエンジンは、データを読み出すRead APIとデータを書き込むWrite APIを提供しており、これらのAPIを通じてデータの入出力が行われます。
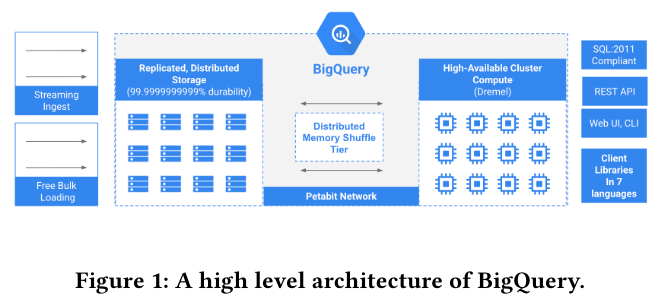
図1 BigQueryのアーキテクチャー(論文より抜粋)
たとえば、BigQueryでクエリーを実行すると、クエリーのコーディネーターは、有向グラフ形式の実行プランを生成して、グラフの各ノードの処理を複数のコンテナに割り当てる事で並列分散処理を行います。この際、有向グラフの末端にあたるリーフノードは、ストレージエンジンからRead APIを用いて必要なデータを読み出した上で、上位のノードに受け渡します。また、BigQueryのテーブルに新しいデータを挿入する際は、外部のデータソースからWrite APIを用いてデータを書き込みます。
このように、ストレージエンジンとクエリーエンジンが分離したアーキテクチャーには、それぞれのパーツが独立に進化できるというメリットもあります。最新のストレージエンジンであるVortexは、Read/Write APIが外部に公開されており、クエリーエンジン以外の外部システムがダイレクトにデータを読み書きすることも可能です。
外部公開されたVortexのRead/Write APIは、Google Cloudでは、BigQuery Storage Read/Write APIという名称で提供されています。Vortex内部のアーキテクチャーとRead/Write APIを通じた外部システムとの関係は、図2のようにまとめられます。
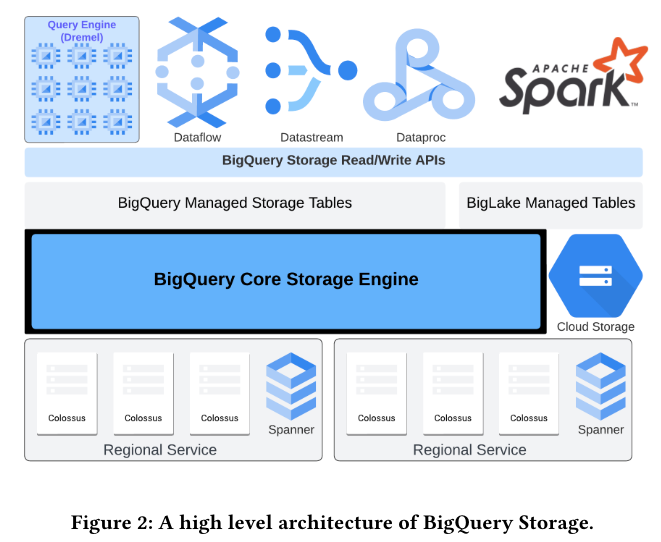
図2 Vortexの構成概要(論文より抜粋)
BigQueryのクエリーエンジンは、この図では、左上の「Query Engine(Dremel)」の部分にあたります。Dremelは、BigQueryの前身となるGoogleの社内システムの名称で、開発当初はストレージエンジンと密に結合したアーキテクチャーでしたが、現在はストレージエンジンから独立したクエリーエンジンの役割を担います。その横にあるDataflowなどは、Read/Write APIを通じてVortexのデータを読み書きする外部システムの例になります。
図2の「BigQuery Storage Read/Write API」の下を見ると、「BigQuery Managed Storage Tables」と「BigLake Managed Tables」という記述があります。BigQuery Managed Storage Tablesは、BigQuery標準のテーブルデータで、もう一方のBigLake Managed Tablesは、Cloud Storageなどに保存したオープンフォーマットのデータファイルをベースとするテーブルデータです。冒頭の論文は、BigQuery標準のテーブルデータを支える「BigQuery Core Storage Engine」としてのVortexのアーキテクチャーを中心に解説しています。
Vortexが管理するデータの実体は、Google標準の分散ファイルシステムであるColossusに永続化されており、関連するメタデータは分散データベースのSpannerに保存されます。図にあるように、複数リージョンのColossusとSpannerにレプリケーションすることで、保存データの冗長化を図っています。
冒頭の論文では、ストレージエンジンとしてのVortexの特徴として、次の点をあげています。
単一のAPIでバッチとストリーミングの両方にどうやって対応するのか不思議に思うかも知れませんが、この部分は書き込み処理のAPI設計に工夫がなされています。Vortex APIのクライアントは、はじめに、「UNBUFFERED」「BUFFERED」「PENDING」のいずれかのタイプを指定して、Streamオブジェクトを取得します。バッチで書き込む場合は、「PENDING」タイプのStreamに対してデータを追加していき、最後にCommit処理を行うと、追加したデータがまとめてテーブルに反映されます。Commit処理を行うまでは、追加したデータは読み出されることはありません。
一方、ストリーミングで書き込む場合は、「UNBUFFERED」、もしくは、「BUFFERED」を指定します。「UNBUFFERED」の場合、個々のデータの追加リクエストに対して成功のレスポンスが返ると、そのタイミングで追加したデータは読み出し可能になります。また、「BUFFERED」の場合は、クライアントは、データを追加しながら必要に応じてFlush処理を実行します。Flush時に指定した行数のデータがそのタイミングで読み出し可能になります。バッチとストリーミング、いずれの場合も複数のStreamオブジェクトを取得して、並列にデータを書き込むことが可能です。
今回は、2024年に公開された論文「Vortex: A Stream-oriented Storage Engine For Big Data Analytics」に基づいて、BigQueryのStorage APIを支えるストレージエンジンであるVortexについて、アーキテクチャーの概要とその特徴を紹介しました。次回は、Vortexのより詳細なアーキテクチャーを解説します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































