
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2024年に公開された論文「Vortex: A Stream-oriented Storage Engine For Big Data Analytics」に基づいて、BigQueryのStorage APIを支えるストレージエンジンであるVortexのアーキテクチャーを解説します。今回は、アーキテクチャーの全体像とデータ書き込み処理の流れを説明します。
Vortexのアーキテクチャー全体は、図1のようにまとめられます。前回の記事の図2にあるように、BigQueryが扱うデータは、標準的には「BigQuery Managed Storage Tables」に保存されます。これは、Dremelなどのクエリーエンジンによる検索処理に最適化されたテーブルで、図1の「Read Optimized Storage(ROS)」に当たります。
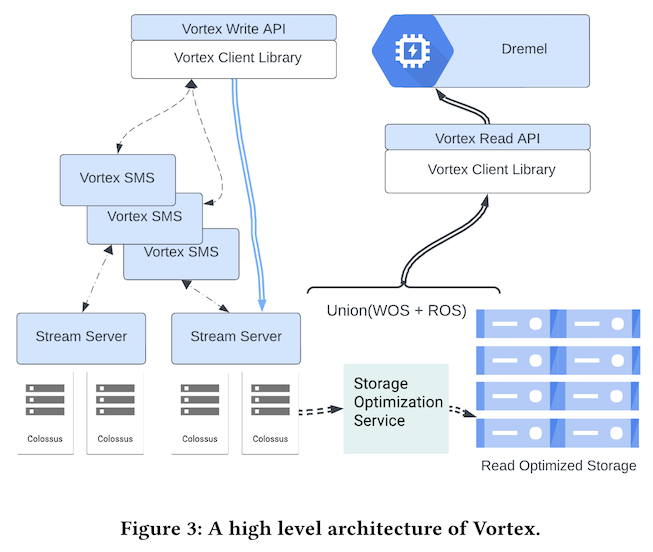
図1 Vortexのアーキテクチャー全体像(論文より抜粋)
図1から分かるように、VortexはWrite APIで受け取ったデータをROSに直接保存するわけではありません。大量のデータを高速に受け取れるように、はじめは、書き込み処理に最適化された形式で「Write Optimized Storage(WOS)」に保存します。この部分の処理は、図1の「Vortex Write API」の直下にあるVortex Client Libraryが行います。ここでいうClient Libraryは、Vortexのシステム内部で利用されるライブラリーで、外部のアプリケーションが使用するライブラリーではないので注意してください。そして、クエリーエンジンや外部アプリケーションがRead APIでデータを読み出す際は、ROSに保存されたデータとWOSに保存されたデータの両方から必要なデータをマージして取り出します。この部分の処理は、「Vortex Read API」の直下にあるVortex Client Libraryが行います。
この際、容易に想像されるように、WOSに保存されたデータが多くなると、高速なデータの読み出しが困難になります。そこで、バックグラウンドで動作するStorage Optimization ServiceがWOSのデータをROSに移動していきます。この部分の処理については、次回に改めて説明します。
ここではまず、Write APIによる書き込み処理の流れを説明します。これは、先ほどの図1の左側にあたる部分で、Vortex Client Libraryは、WOSのメタデータを管理するVortex SMS(Stream Metadata Server)、および、実際のデータ書き込み処理を行うStream Serverとやりとりをします。Vortex SMSが管理するメタデータは、Spannerに保存されます。また、Vertex SMSとStream Serverは、いずれも複数のコンテナでスケールアウトするようになっており、それぞれの負荷状況に応じて、実際に使用するコンテナが選択されます。
それでは、これらのコンポーネントが行う処理を図2に従って説明します。
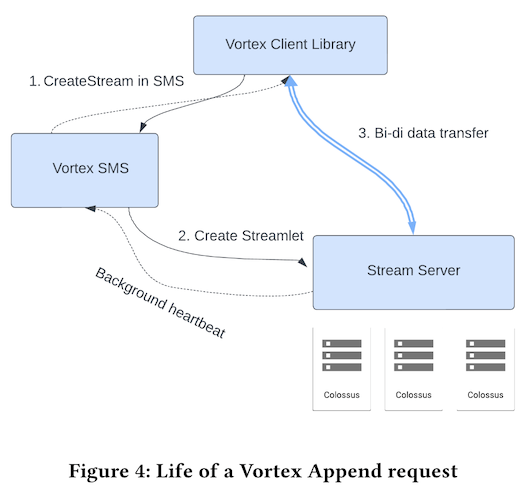
図2 データ書き込み時の処理の流れ(論文より抜粋)
前回説明したように、Write APIでデータを書き込む際は、はじめにStreamオブジェクトを取得します。これは、内部的には、Vortex Client LibraryがVortex SMSにStreamの作成を依頼する処理にあたります。この時、Vortex SMSは、Streamに書き込まれたデータを保存するStreamletを定義して、該当のStreamletへの書き込み処理を担当するStream Serverを割り当てます。Streamletは、特定のテーブルに所属する、新たに書き込まれた行データの集まりです。
そして、割り当てられたStream Serverの情報を受け取ったClient Libraryは、Streamに書き込まれたデータを該当のStream Serverに転送していきます。Streamletの実体は、一定サイズのFragmentの集まりで、個々のFragmentはColossus上の追記型ログファイルになります。つまり、Streamletに対するデータを受け取ったStream Serverは、Fragmentを作成して、そこに行データを追記していきます。Fragmentに対応するログファイルが一定のサイズに達すると、そのFragmentはクローズされて、新しいFragmentを作成するという流れになります。クローズされたFragmentは、前述のStorage Optimization ServiceによるROSへの移動対象となります。
また、Stream Serverが管理するStreamlet(および、その実体となるFragment)のメタデータは定期的にVortex SMSに送信されて、Spannerに書き込まれます。Storage Optimization Serviceは、Vortex SMSが管理するメタデータから、クローズされたFragmentの情報を取得します。なお、Stream ServerがFragmentにデータを書き込む際は、2MB単位でのデータ圧縮処理とユーザー個別の暗号化鍵を用いた暗号化処理を行います。また、前回説明したように、書き込み中のデータは、Commit、もしくは、Flush処理を行った時点で読み出し可能になります。これに対応して、Fragmentの内部には、どの行までが読み出し可能かを示す情報も記録されます。
今回は、2024年に公開された論文「Vortex: A Stream-oriented Storage Engine For Big Data Analytics」に基づいて、BigQueryのStorage APIを支えるストレージエンジンであるVortexについて、アーキテクチャーの全体像とデータ書き込み処理の流れを説明しました。次回は、Storage Optimization Serviceの処理内容と実環境での性能データを紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































