
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2023年に公開された論文「Profiling Hyperscale Big Data Processing」に基づいて、Googleの大規模データ処理システムのプロファイリングデータを紹介します。今回は、実際に収集されたプロファイリングデータについて説明します。
システムプロファイリングの目的は、システムを構成するどの部分、もしくは、どのような処理に実行時間が割かれているのかを分析することです。そこで、まずは、処理時間を計測する部分をいくつかのカテゴリーに分けておきます。冒頭の論文では、次のように、3つの階層に分けて段階的にカテゴリーを分割しています。
まずはじめに、システムの処理時間を次の3つに分割します。
最後のリモートサービスの内容はシステムによって異なりますが、Spannerであれば、同期処理のためのコンセンサスプロトコルの完了待ち時間、BigTableであれば、リモートストレージのコンパクション処理、そして、BigQueryであれば、ステージ間のシャフル処理などがあります。この3つのカテゴリーの処理時間は、第164回からの
記事で紹介した、分散トレーシングツールのDapperで計測できます。
続いて、「システムを構成するノードによるCPU処理時間」をさらに次の3つに分割します。
最後に、これら3つのカテゴリーのそれぞれをより詳細な項目へと分割します。具体的な項目は次回に説明しますが、これらの処理時間は、専用のプロファイリングツールを用いて、2022年の特定の日に1日分のデータを収集したということです。
はじめに、最上位の分割にあたる、CPU、I/O、リモートサービスの分布を表すデータを紹介します。具体的な計測結果は、図1のようになります。それぞれのグラフの左端の「Overall Average」が全データの平均値で、例えば、SpannerとBigTableは、全体の50%以上はCPUによる処理時間が占めています。一方、BigQueryは、CPUとI/Oの時間がどちらも40%程度で均衡しています。
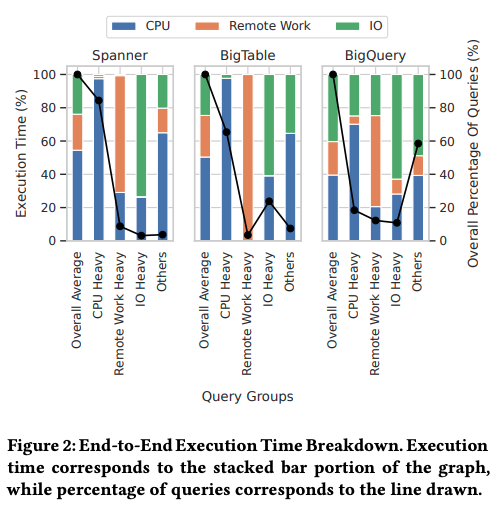
図1 CPU、I/O、リモートサービスの分布(論文より抜粋)
その他のグラフは、システムが処理するクエリーを次の条件で分類して、それぞれのカテゴリーのデータだけを取り出した場合の結果を表します。各カテゴリーの割合は、折れ線グラフで示されています。
これらのグラフを見ると、SpannerとBigTableは、「CPU Heavy」に属するクエリーの割合が非常に多く、CPU処理を補助するアクセラレーターの導入が効果的と考えられます。一方、BigQueryは、それぞれのカテゴリーのクエリーが入り混じっており、CPU処理の高速化だけではなく、分散ストレージやリモートサービスの高速化もあわせて考える必要があります。
続いて、CPU処理時間を先に説明した3種類に分類した場合の内訳は、図2のようになります。一般に単一のサーバーで処理をするシステムの場合、「Core Compute」の割合が大きくなりますが、これらのシステムでは、「Core Compute」の割合は40%以下に抑えられています。つまり、大規模分散システムに固有の処理に伴うオーバーヘッドが大きな割合を占めており、アプリケーションとして行うデータ処理だけではなく、その他の処理もあわせて高速化する必要があります。
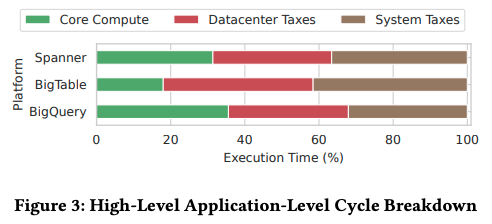
図2 CPU処理時間の内訳(論文より抜粋)
ここまでの結果を総合すると、単一のアクセラレーターを導入して、ボトルネックになっている特定の処理だけを高速化するのではなく、複数のアクセラレーターによりシステムのさまざまな処理をまんべんなく高速化するアプローチが求められることがわかります。
今回は、2023年に公開された論文「Profiling Hyperscale Big Data Processing」に基づいて、Googleを代表する大規模データ処理システムから収集されたプロファイリングデータを紹介しました。次回は、「Core Compute」「Datacenter Tax」「System Tax」、それぞれの内訳の詳細を紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































