
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2010年に公開された論文「Dapper, a Large-Scale Distributed Systems Tracing Infrastructure」に基づいて、Google社内で使用されている分散トレーシングツールDapperを紹介していきます。マイクロサービスアーキテクチャーの環境では、クライアントからのリクエストを処理する際に、複数のサービス呼び出しのツリーが発生します。このような複数サービスの連携状況を把握して、さらに、処理時間のボトルネックを発見することが分散トレーシングツールの役割です。
冒頭の論文では、Web検索のシステムを例に分散トレーシングツールの必要性を説明しています。GoogleのWeb検索システムでは、1つの検索リクエストに対して、数千以上のサービスに対する呼び出しのツリーが発生します(図1)。Web検索では、検索リクエストへの応答時間を短く保つことが重要ですが、そのためには、1つのリクエストに対して、どのサービスがどれだけの処理時間を要しているかを把握する必要があります。この時に役立つのが分散トレーシングツールです。
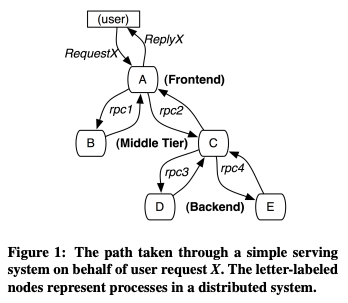
図1 複数サービスに対する呼び出しのツリー(論文より抜粋)
分散トレーシングツールを使用すると、図2のように、ツリー状に広がるサービス呼び出しの関係性と、それぞれのサービスの処理時間が可視化できます。これにより、1つの処理に関連するサービスの全体像と処理時間のボトルネックが把握できます。
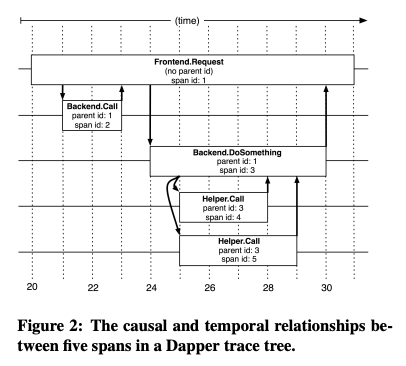
図2 分散トレーシングツールによるトレースデータの例(論文より抜粋)
この際、関連するすべてのサービスに同一のトレーシングツールが適用されており、継続的にモニタリングできることが大切です。Web検索に関連する数千以上のサービスは、複数のチームによって開発されており、チームごとにトレーシングツールが異なったり、トレーシングツールを適用していないチームがあると問題になります。このような問題を避けるために、Dapperの開発チームは、次の3つのデザインゴールを設定しました。
まず、高度にチューニングされたサービスでは、トレーシングツールの導入にともなうオーバーヘッドがサービスそのものの性能に悪影響を及ぼす可能性があります。サービスの開発チームがそのような悪影響を気にせずに導入できる必要があります。また、トレーシングツールを導入する際に、アプリケーションコードに大きな変更が必要になると、サービスの開発者が導入を嫌がる可能性があります。また、コードの変更方法を誤って、トレーシングツールが正しく動作しない可能性も高くなります。このような問題を避けるために、アプリケーションコードを大きく変更せずに簡単に導入できる必要があります。そして、数千以上のサービスにまたがるトレースを高速に処理できるスケーラビリティも必要です。
Dapperが収集するトレースデータは、先の図2に示したように、それぞれのサービスのリクエスト処理時間(開始時刻と終了時刻)を表す「Span」の集合になります。それぞれのSpanには、アプリケーション開発者が自由に指定できる名前(Span name)と、自動生成されるユニークなSpan IDが付与されており、そのSpanの呼び出し元となるSpanのID(Parent ID)も同時に記録されます。また、Spanが連なったツリー全体にもユニークなID(Trace ID)が付与されます。そして、Spanのログデータを収集する仕組みの全体像は、図3のようになります。
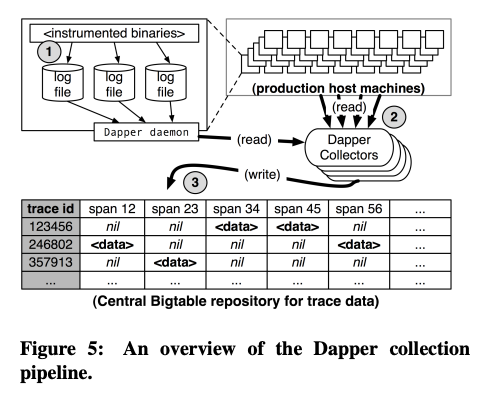
図3 Dapperのアーキテクチャー(論文より抜粋)
それぞれのサービスが生成するSpanのログデータは、サービスが稼働するサーバーのローカルに保存された後、別のサーバーで稼働するDapper Collectorsが収集して、Bigtableに書き込みます。この際、1つのツリーに含まれるすべてのSpanは、まとめて1つの行に保存されて、Trace IDがその行のキーになります。サービスが生成したログは、平均的には15秒以内にBigtableに保存されて検索可能になりますが、状況によっては、数分から数時間かかる場合もあります。
ここで重要になるのが、それぞれのサービスがSpanのログデータを生成する方法です。前述のように、アプリケーションのコードに大きな変更を加えるのは好ましくないため、Dapperの開発チームは、社内標準のRPCフレームワークにこの機能を組み込みました。Google社内でサービスを開発するエンジニアは、ほとんどの場合、このフレームワークを使用してサービスの呼び出しを行うので、アプリケーション開発者はDapperの存在を意識する必要がありません。
一方、Dapperのアノテーション機能を利用すると、アプリケーション開発者が意図的にメッセージを出力することもできます。図4のように、専用のライブラリを使用すると、Spanのログデータに対して、トレースの解析に有用な情報を追加できます。実際のログデータを解析すると、現在、70%のSpanのログデータに対して、アノテーション機能を用いたメッセージが付与されているということです。

図4 Dapperのアノテーション機能を使用するコードの例(論文より抜粋)
今回は、2010年に公開された論文「Dapper, a Large-Scale Distributed Systems Tracing Infrastructure」に基づいて、Google社内で使用されている分散トレーシングツールDapperのアーキテクチャーを紹介しました。次回は、Dapperの性能に関する情報と、Dapperを利用したデータ分析ツールを紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































