
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回は、2024年に公開された論文「Productive Coverage: Improving the Actionability of Code Coverage」を紹介します。この論文では、テストコードの実行範囲を調べるコードカバレッジツールに、対応を検討した方がよさそうなポイントを自動で指摘する機能を追加した事例が紹介されています。一見すると地味な機能ですが、技術的な仕組みや機能追加による改善効果の調査方法など、技術的な観点から興味を引く内容の論文です。
Google社内のソフトウェア開発プロセスでは、リポジトリのコードを修正する際は、関連する変更をまとめたCL(チェンジリスト)の単位でレビューが行われます。第42回の記事「Googleのソフトウェア開発におけるコードレビューの役割」で紹介したように、オープンソースのレビューツールであるGerritに類似のツールを用いて、コードの変更部分についてレビュアーと開発者がコメントをやり取りしながら、コードの再修正などを行っていきます。このレビューツールには、ソースコードの内容をチェックするさまざまなツールが組み込まれており、人間のレビュアーからのコメントに加えて、これらのツールの実行結果もあわせて確認できます。
このようなツールの1つにコードカバレッジツールがあり、これは、テストコードを実行した際に、テスト対象のコードのどの部分が実行されるかをチェックします。図1の例では、行番号の背景が緑色の所が実行された部分で、オレンジ色の所は実行されなかった部分になります。(色がついていない所は、関数の宣言部分など、直接の実行対象にはならない部分です。)これにより、本来テストするべき部分に対して、適切なテストコードが用意されていないなどの状況が発見できます。

図1 コードカバレッジツールの結果表示の例(論文より抜粋)
ただし、既存のコードカバレッジツールは、テストされていない部分を機械的にチェックして表示するだけで、どの部分にテストを追加した方がよいかは、レビュアーが判断する必要があります。そこで、この論文では、テストの追加が必要と思われる部分を自動判定して、「ここはテストを追加した方がいいですよ」というコメントを自動でつける機能について議論しています。図2の例では、193行目はテストが実行されなかった部分ですが、ここに対して、単体テストを追加した方がよさそうというコメントを残しています。このコメントを見たレビュアーが、実際にテストの追加が必要と思った場合は、「Please fix」ボタンを押すと、開発者にテストの追加を依頼するコメントが自動で付けられます。また、右下のThumbs-up / downボタンで、この自動コメントの有用性をフィードバックすることもできます。
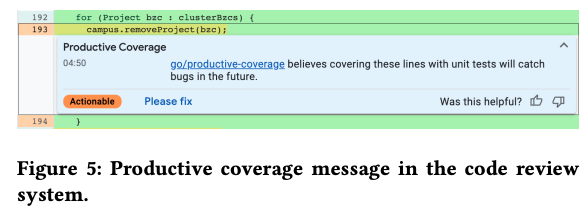
図2 テストの追加を示唆する自動コメントの例(論文より抜粋)
ここまでの説明を読むと、コードカバレッジツールのちょっとした機能拡張の話題のようにも見えますが、この論文の興味深い所は、非常に現実的な視点で自動判定のアルゴリズムを考えている点と、新機能の効果をデータに基づいて客観的に分析している点です。まず、テストが必要かどうかは、対象のコードに類似したコードをリポジトリ全体から検索して、それらが頻繁にテストされているか、もしくは、頻繁に本番環境で実行されているか、という実績ベースでの判定を行います。第20回の記事「Googleのソースコード管理システム ― Piper/CitC」で紹介したように、Googleの社内で開発しているソフトウェアは、すべてのコードが単一のリポジトリに格納されており、それぞれのコードの実行状況がサンプリングによって記録されています。このような既存のインフラを活用した仕組みと言えるでしょう。
コードの類似性による判定では、n-gramによる完全一致を利用します。まず、事前準備として、リポジトリ内の既存のコードすべてをn-gramのリストに分解します。たとえば、"setContext()" のような単一の命令は、そのまま "setContext" という要素にして、"x = complicated.Function(238)" のような複合命令は、(x, complicated), (complicated, Function) のように連続する2つの構成要素のペアに変換します。最後に、"One two three four" のような文字列は、(one, two, three), (two, three, four) のように連続する3つの構成要素のペアに変換します。その上で、(x, complicated) や (one, two, three) などの各パートに対して、これまでにテストが何回実行されたか、あるいは、本番環境での実行時間(CPUの累積処理時間)などのログ情報を収集します。さらに、コード内に同一のペアが複数あった場合は、それぞれの値を合計します。つまり、コード内の (x, complicated) や (one, two, three) などのあらゆる組み合わせに対して、リポジトリ全体におけるテスト回数や実行時間が記録されたデータベースができあがります。より正確には、テスト回数や実行時間をもとに計算した「重要度のスコア(0~1の範囲)」が記録されます。
その後、新しい判定対象のコードが与えられると、該当コードを同様のn-gramのリストに分解した上で、リスト内の各要素に対するスコアを先のデータベースから取得します。各要素に対する値を合計して正規化したものが、該当コードの総合スコアになります。総合スコアが高いほど、既存のリポジトリ内でテスト回数や実行時間が多い、重要なコードという判定ができます。ただし、これまでに使われていなかった新しいライブラリのコードなどは、既存のリポジトリ内に対応するコードが存在せず、結果的に重要度が低いと判定されますが、これはテスト対象からはずすべきではありません。そのため、マッチするコードの数が一定値より低い場合は、強制的にスコアを大きく設定します。
ちなみに、(x, complicated) や (one, two, three) などのキーワードのペアは、リポジトリ全体で考えると膨大な数の組み合わせになるので、それなりの大きさのデータベースができあがりそうですが、この点についても工夫がなされています。このデータベースの目的は、重要度が一定値より高いものを発見することであり、重要度の値そのものを正確に計算する必要はありません。そこで、それぞれのキーワードペアについて、対応するスコアが0.5以下のものだけをデータベースに登録しておき、データベースに存在しないキーワードペアのスコアは一律に1.0として取り扱います。この場合、リポジトリに存在しないキーワードペアのスコアは1.0になりますが、これは、既存のリポジトリに存在しないコードには高い重要度を与えると言う前述のルールに適合した取り扱いになります。
この条件の元に、実際にデータベースに記録されたペア(n-gram)の個数は図3のようになります。「Number of n-grams」の行が各言語に対するn-gramの個数で、その下は、命令要素と文字列要素の割合を示します。この程度の数であれば、すべてのデータをメモリに載せることができるので、n-gramに対するハッシュ値をインデックスにして、高速に検索できます。
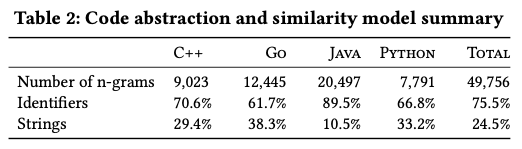
図3 リポジトリ全体でのn-gramの個数(論文より抜粋)
コードの類似性判定というと、最近であれば、LLMを用いた処理を想像する方も多いかもしれませんが、リポジトリに含まれる膨大なコードに対して計算負荷の高いLLMを利用するのは効率的とは言えません。プログラムコードのようにパターンが限られたものであれば、このような方法で十分に判定が可能です。この機能をレビューツールに組み込む際は、テストが実行されていない部分のそれぞれに対してスコアを計算して、スコアが高いものに対して図2の自動コメントを追加する流れになります。
今回は、2024年に公開された論文「Productive Coverage: Improving the Actionability of Code Coverage」に基づいてコードカバレッジツールの機能拡張について説明しました。次回は、この機能が実際のレビュープロセスに及ぼす効果について紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes

























