
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2024年に公開された論文「Load is not what you should balance: Introducing Prequal」に基づいて、GoogleのコンテナインフラであるBorg環境の特性に対応した、新しいロードバランシングの仕組みである「Prequal」を紹介していきます。今回は、Prequalの設計目標とアーキテクチャーの概要を説明します。
前回の記事で説明した従来のロードバランサーの課題、および、Prequalの設計目標を改めて整理します。まず、従来のロードバランサーは、各コンテナのCPU使用率、すなわち、割り当てられたCPU使用量の何%を消費しているかを指標として、リクエストを転送するコンテナを決定します。しかしながら、CPU使用率は一定期間の平均値として計算されるものなので、原理的に「リアルタイムでの評価」が困難になります。前回の記事の図1で見たように、秒単位でCPU使用率が100%を超えていても、1分単位のCPU使用率ではそれを捉えることができません。そのため、CPU使用率に余裕があると判断してリクエストを転送したコンテナが、実際にそのリクエストを処理するタイミングではCPU使用率に余裕がない可能性があります。つまり、運が悪いと該当リクエストの処理に遅延が発生します。
実際にこのような現象が発生する確率(言い換えると「運の悪さ」)はそれほど大きくないとしても、膨大なユーザーがアクセスするサービスでは、ごく一部のユーザーに与える悪影響も無視することはできません。実際の所、Prequalを導入する以前のYouTubeのトップページでは、処理遅延に伴うエラーでSLOが満たせない状況が起きていたことが論文内で説明されています。
そこで、Prequalでは、CPU使用率に代わる指標を用いて、処理時間(レイテンシー)のロングテールを削減することを設計目標の1つとしています。この際、より短いタイミングでCPU使用率を測定するなどの方法も考えられますが、指標の測定処理自体の負荷で、本来のリクエスト処理が遅くなる可能性もあります。そこで、Prequalの開発チームは、測定処理の負荷が低く、かつ、レイテンシーのロングテール削減に効果のある仕組みの実現を目指しました。
Prequalは、CPU使用率に代わる負荷指標として、「レイテンシー」と「RIF(Request in flight/処理中のリクエスト数)」を採用しています。レイテンシーは、直近のリクエストを処理するのにかかった実時間です。レイテンシーのロングテールを削減するという目標に直接合致する指標であり、測定のために特別な仕組みを導入する必要もありません。さらに、1秒間に多数のリクエストを処理するシステムでは、1秒以下の鮮度の情報が得られることになります。
もう一つのRIFは、該当のコンテナ上で処理中のリクエストの総数です。マイクロサービスの多くは、I/O処理の待ち時間などを無駄にしないように、複数のリクエストを並列処理するように実装されており、これによる同時処理中のリクエスト数がRIFになります。先ほどのレイテンシーが「直近のレイテンシー」の実測値にあたるのに対して、RIFは「この後のレイテンシー」に相関を持つ情報と言えるでしょう。こちらも測定のための特別な仕組みは不要です。
また、RIFは、コンテナのメモリー使用量にも大きく影響します。CPU使用量と異なり、メモリー使用量はオーバーコミットできませんので、メモリー使用量の上限を超える状況は、より積極的に避ける必要があります。そのため、Prequalは、レイテンシーが低くてもRIFが大きいコンテナは、リクエスト転送先から除外するように実装されています。
Prequalは、1つのシステムを構成する複数のマイクロサービス間でのロードバランシングに使用されるので、リクエストを送信するクライアントとそれを受けるサーバーの間に専用のロードバランサーを置くのではなく、クライアント側にロードバランシングの機能を持たせることも可能です。実環境では、図1のように両方の構成が使用されています。図1の左は、クライアントがPrequalのクライアント機能を持つ場合、図1の中央は、Prequalのクライアント機能を持ったロードバランサーを設置する場合になります。また、図1の右のように、マイクロサービスの処理がツリー状にブランチする場合、Prequalを使用する部分と使用しない部分が混在することもあります。
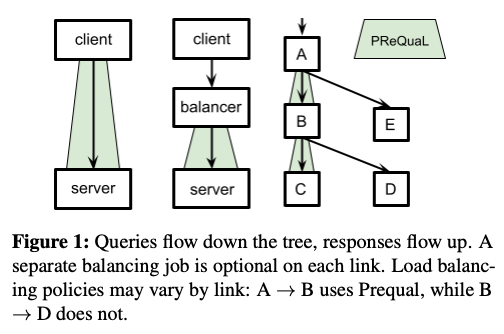
図1 Prequalのデプロイパターン(論文より抜粋)
Prequalのクライアントは、特定のタイミングでサーバー側のコンテナの指標値を取得して、ローカルのプールに保存します。そして、プールに保存された情報に基づいて、リクエストを転送するコンテナを決定します。リクエストを転送するタイミングで、すべてのコンテナの最新の指標を取得するのが最適と考えるかもしれませんが、指標の取得処理自体に時間がかかったり、取得処理の負荷が大きくなってしまうと意味がありません。この部分のバランスを取るために、取得した指標値をプールに保存しながら、プール内の情報が古くなりすぎない仕組みを実現しています。この部分の詳細は、次回に改めて解説します。
今回は、2024年に公開された論文「Load is not what you should balance: Introducing Prequal」に基づいて、Prequalの設計目標とアーキテクチャーの概要を説明しました。次回は、Prequalがリクエスト転送先のコンテナを決定するロジックの詳細を説明します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes


































