
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2023年に公開された論文「Improving Network Availability with Protective ReRoute」に基づいて、Protective ReRoute(PRR)と呼ばれる、ネットワーク通信の信頼性を向上するGoogle独自の仕組みを紹介します。今回は、本番環境における実際の効果を示すデータを紹介します。
Googleのネットワーク環境では、ネットワークの障害状況をモニタリングするために、事前に定義された複数のIPアドレス間で疎通確認用の通信を継続的に行っています。この論文では、特に、UDPパケットによるIP通信とStubby(Google社内版のgRPC)によるRPC通信を用いた、L3、および、L7レイヤーでのモニタリングデータを用いて、ネットワーク障害に対するPRRの効果を検証しています。Stubbyによる疎通確認は、PRRを有効にしたものと無効にしたものがあり、これらを比較することで、アプリケーションレベルで見たPRRの効果が確認できます。
論文内ではいくつかの具体的な事例が取り上げられており、複数の要因が重なった稀な障害においても、PRRによってアプリケーションに対する影響が低く抑えられたことがわかるデータが紹介されています。その中の1つが、14分間続いたB4ネットワークの障害です。特定のロケーションにおいて冗長化された電源設備が同時に故障して、該当ロケーションにあるB4を構成する一群のスイッチが停止した上に、稼働中のスイッチもSDNコントローラーから切り離された状態になりました。さらに、これとは別のメンテナンス作業の影響で自動回復のプロセスも遅延するという状況でした。図1は、この際の大陸間の通信状況を表すグラフです。
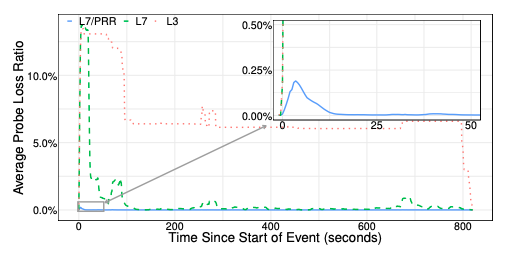
図1 B4ネットワーク障害時のモニタリングデータ(論文より抜粋)
まず、L3レイヤーでの通信状況(赤の点線)を見ると、障害発生直後は約13%のパケットがロスしています。言い換えると、モニタリングしていた経路の約13%に障害が発生しています。前述のように、該当ロケーションの自動回復が進まないため、この状況が長く続いています。100秒後にグローバルな経路変更が行われて少し改善されましたが、それでも7%程度のパケットロスが残っています。最終的に800秒が経過した所で、該当ロケーションを通る経路がすべて排除されて、L3レイヤーでの通信が完全に回復しています。
一方、(PRRを無効にした)L7レイヤーでの通信状況(緑の点線)を見ると、障害発生後はL3レイヤーと同じ割合のパケットロスが発生しますが、約20秒後にパケットロスの割合が大きく減少しています。これは、Stubbyのプロトコルによるタイムアウトが発生して、RPCのセッションを張り直したことによります。この際、使用するポート番号が変わるためにパケットヘッダーの情報が変化して、ECMPで選択される経路が変わりますが、障害のある経路は全体の約13%ですので、セッションを張り直した通信の約87%は正常な経路に戻ります。一見すると、これはPRRによる回復処理と同じ原理のようですが、PRRとは、復旧までの時間のスケールが異なります。PRRは、より低いレイヤー(L4レイヤー)で、1秒以下のスケールでタイムアウトが発生します。そのため、より高速に回復することができます。
実際、PRRを有効化した場合のグラフ(水色の実線)を見ると、障害発生直後のピークでも、パケットロスの割合は0.25%以下に抑えられており、15秒以内にほぼ0%まで減少しています。つまり、PRRを有効化した環境では、アプリケーションの観点からは、この障害の影響はほとんど無かったことになります。
この論文では、2023年の6ヶ月間に収集したモニタリングデータを分析して、ネットワークの可用性向上にPRRが寄与した割合を計算しており、図2がその結果になります。先ほど見たように、L7レイヤーだけでも回復効果がありますが、PRRを併用することで、さらに回復効果が高まります。これを示したのが緑色のグラフです。たとえば、B2ネットワークの大陸内通信(B2:Intra)では、PRRによって、ユーザーに影響のある障害が発生している時間が75%以上削減されています。
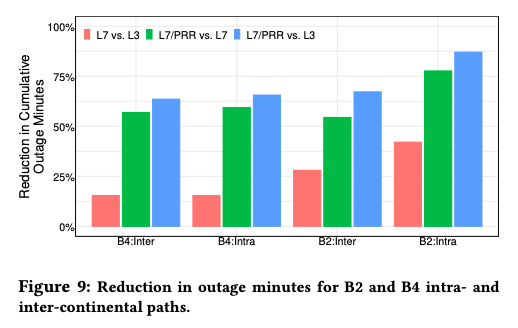
図2 PRRによる障害発生時間の減少効果(論文より抜粋)
一般に可用性の値を示す時に、「X-9」という言い方をします。Four-9は99.99%の可用性、Five-9は99.999%の可用性という具合です。障害発生中の時間を90%減らすことで、9の数を1つ増やすことができますので、75%の削減であれば、9の数を約0.8個増やす効果があったと言えるでしょう。
Google Cloudのプロジェクト環境で動作するVMインスタンスにもPRRが適用されています。Google Cloudで稼働するVMインスタンスが送受信するパケットは、PSPと呼ばれる仕組みで暗号化されており、図3のように、暗号化されたVMパケットに対して、外部ヘッダーが付与された構造を持ちます。
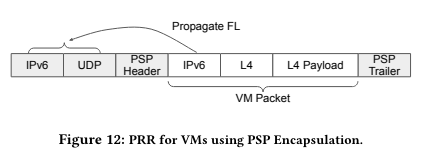
図3 PSP暗号化パケットの構造(論文より抜粋)
PRRに対応したVMインスタンスのゲストOSは、ネットワーク障害を検知すると、VMパケット内のフローラベルを変更しますが、PRRによる経路選択は外部ヘッダーのフローラベルによって行われるので、この変更を外部ヘッダーのフローラベルにも反映する必要があります。そこで、VMパケットのIPv6ヘッダーのハッシュ値を外部ヘッダーのフローラベルに埋め込むことで、VMパケットのフローラベルの変更を外部ヘッダーのフローラベルに反映する仕組みが実装されています。
今回は、2023年に公開された論文「Improving Network Availability with Protective ReRoute」に基づいて、ネットワーク通信の信頼性を向上するGoogle独自の仕組みであるProtective ReRoute(PRR)について、本番環境における実際の効果を示すデータを紹介しました。論文では、ここで紹介した以外の障害パターンについても同様のデータが公開されています。
次回は、BigQueryの高性能なストリーミングデータ入力を実現するStorage Write APIに関する話題をお届けします。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes

























