
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
前回に続いて、2023年に公開された論文「Improving Network Availability with Protective ReRoute」に基づいて、Protective ReRoute(PRR)と呼ばれる、ネットワーク通信の信頼性を向上するGoogle独自の仕組みを紹介します。今回は、シミュレーションによるPRRの動作検証の結果を紹介します。
前回の記事で説明したように、PRRでは、TCPセッションに伴うOS上のネットワーク処理を利用して通信障害を検知して、パケットヘッダーに含まれるフローラベルを変更することで通信経路を切り替えます。TCPパケットの送信側では、送信パケットに対する受信応答(ACK)パケットをRTOで設定された時間内に受け取らない場合に、通信経路に障害が発生したと認識します。また、受信側から送信側に向けた経路(戻り経路)に障害がある場合は、受信側でも障害を検知する必要があります。この場合は、送信側が同じパケットを再送するので、受信側には、同じパケットを2回受信するPacket Duplicationのイベントが発生します。受信側はこのイベントによって、通信経路に障害が発生したことを認識します。このような送信側と受信側の処理の違いがあるため、障害の発生パターンによって、復旧に至るまでの処理の流れが変化します。図1は、2種類の具体例を示したものです。
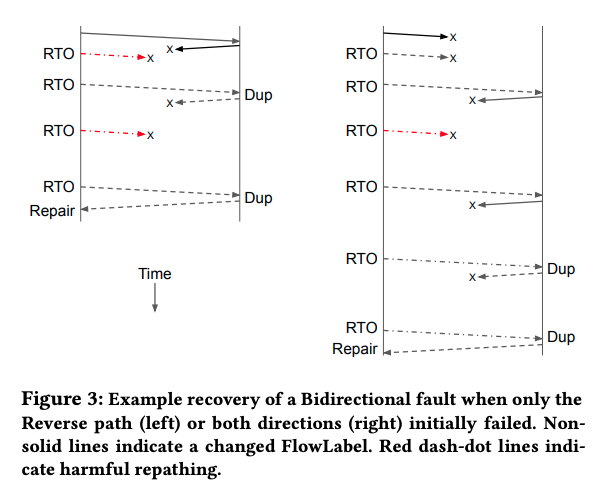
図1 復旧までの処理の流れの例(論文より抜粋)
左の図では、はじめに、戻り経路に障害が発生してパケットがロスします。その後、送信側は行き経路を変更してパケットを再送します。このパターンの場合、送信側の経路変更は不要ですが、送信側からはどちらの方向の経路に障害が発生しているかは判別できない点に注意してください。ところが、このタイミングで行き経路にも障害が発生して、このパケットもロスします。送信側が、再度、経路を変更してパケットを再送すると、これは受信側に到達して、Packet Duplicationのイベントが発生します。ここで、受信側は戻り経路を変更して応答パケットを送信しますが、運悪く、変更後の経路にも障害があり、応答パケットがロスします。このようなやりとりが繰り返された後、最終的に、両方向において障害のない経路が選択されると、ここで通信が復旧します。同じく右の図は、両方向の経路に同時に障害が発生した場合に起こり得る例の1つです。また、図1において、パケットを再送するまでの時間間隔が徐々に増えている点に注意してください。これは、TCP通信のExponential backoff機能によって、再送を繰り返す際の時間間隔が指数関数的に増えることによるものです。
このように、PRRでは変更後の経路が正常である保証がないため、復旧に至るまでの時間は確率的に変化します。そこでこの論文では、障害パターンの違いによる復旧までの時間の変化をシミュレーションで確認しています。具体的には、20,000組のTCPセッションが存在する状況で、一定割合の経路に障害を発生させて、「障害状態」のセッション数が時間と共に減少する様子を観察します(図2)。ここでは、受信応答(ACK)パケットを2秒以上受け取っていないものを障害状態のセッションと定義します。
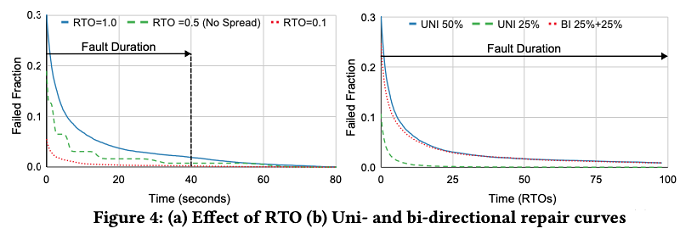
図2 シミュレーションによる復旧状況の確認結果(論文より抜粋)
図2の左は、50%の経路に双方向の障害が発生したものとして、障害状態のセッション数の変化がRTOの初期値によってどのように変化するかを調べた結果です。RTO=0.1は近接する都市間での通信、RTO=1.0は大陸をまたぐ長距離の通信を想定した値です。
まず、RTOの初期値によらずに、障害状態のセッション数は指数関数的に減少しています。そして、RTOの初期値が小さいほど、より早く減少することも読み取れます。直感にも合致した結果です。なお、それぞれのセッションのRTOの初期値は、まったく同じ値ではなく、乱数によるゆらぎを持たせています。この際、RTO=0.5のシミュレーションでは、ゆらぎの幅を極端に小さくしています。そのため、すべてのセッションがほぼ同じタイミングで経路を変更しており、グラフが階段状に変化します。50%の経路に障害が発生しているので、障害がある経路上のすべてのセッションがランダムに経路を変更すると、その中の約50%は障害のない経路に切り替わるので、障害状態のセッションは約半分に減少します。これが繰り返される結果、障害状態のセッション数が指数関数的に減少します。
また、このシミュレーションでは、シミュレーションを開始してから40秒後に、ネットワーク経路の障害が回復したというシナリオになっています。しかしながら、グラフを見ると、40秒を超えても障害状態のセッションが残っています。これは、この時刻まで通信が回復していないセッションでは、パケットの再送を繰り返した結果、RTOの値が大きくなっており、次のパケット再送までの待ち時間があるためです。ネットワーク側で障害が回復したとしても、実際のパケットのやりとりが始まらなければ、アプリケーションの観点では回復したと言えない点に注意してください。
次に、図2の右は、RTOを固定して、障害が発生する経路の割合を変化させた場合の結果です。UNI50%とUNI25%は、一方向の経路の50%、および、25%に障害が発生した場合になります。UNI25%の方がより早く障害状態のセッションが減少していますが、これは、新しく選ばれた経路が、再度、障害のある経路に当たる確率の違いによるものです。UNI50%では、1回の経路変更で約50%のセッションが復旧するのに対して、UNI25%では約75%のセッションが復旧します。これから分かるように、障害が発生した経路の割合が少ない場合、PRRを利用すると、かなり高速に復旧することができます。左のグラフをもう一度見ると、50%の経路に障害が発生した場合でも、RTO=0.1の場合、95%以上のセッションが1~2秒以内に復旧していることが読み取れます。
最後に、BI25%+25%は、両方向の経路のそれぞれ25%に障害が発生した場合です。UNI50%とほぼ同じ形のグラフになっており、復旧にかかる時間は、経路の方向に関係なく、障害が発生した経路の全体的な割合で決まることがわかります。
今回は、2023年に公開された論文「Improving Network Availability with Protective ReRoute」に基づいて、ネットワーク通信の信頼性を向上するGoogle独自の仕組みであるProtective ReRoute(PRR)について、シミュレーションによるPRRの動作検証の結果を紹介しました。次回は、本番環境における実際の効果を示すデータを紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
































