
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2023年に公開された論文「Improving Network Availability with Protective ReRoute」に基づいて、Protective ReRoute(PRR)と呼ばれる、ネットワーク通信の信頼性を向上するGoogle独自の仕組みを紹介します。今回は、PRRの役割とその基本的な仕組みを解説します。
Googleが管理するネットワーク環境については、これまでの記事でも何度か取り上げてきました。大きな構成要素としては、データセンターネットワークのJupiter、データセンター間を相互接続するB4ネットワーク、データセンターとインターネットを相互接続するB2ネットワーク、そして、これらをソフトウェアで管理するSoftware Defined Network(SDN)の技術があります。それぞれの詳細は、次の記事が参考になるでしょう。
いずれのネットワークにおいても複数の通信経路による冗長化が行われており、一部の通信経路に障害が発生した際は、該当の経路を使用しないようにSDNコントローラーが自動的に経路を変更します。この際、新しい経路への変更処理は階層的に行われます。はじめに障害で途切れた通信処理を回復する局所的な変更が行われて、その後、ネットワーク全体で通信経路を最適化する大域的な変更が行われます。しかしながら、障害の種類によっては、SDNコントローラーが障害を認識して、必要な回復処理を行うまでに時間がかかる場合があります。たとえば、ネットワークスイッチのソフトウェア的な障害で、特定のポートで受け取ったパケットをスイッチ内部で破棄する動きをした場合、周りのスイッチからはポートダウンと認識されないため、すぐには障害を認識することができません。
このような場合、一番最初に通信障害を認識するのは、サーバー上のOS機能になります。たとえば、TCPプロトコルによる通信であれば、送信したパケットに対する受信応答(ACK)パケットが一定時間内に戻らない場合、サーバー上のOSは同じパケットを再送します。このタイミングでネットワーク経路を切り替えれば、より短時間で障害から回復できます。このように、ネットワーク通信経路の障害をサーバー側で認識して動的に経路を切り替えることで、短時間での障害回復を図ることがPRRの役割になります。
サーバー側で動的に通信経路を切り替えるには、どのような方法が考えられるでしょうか? PRRでは、ECMPによるマルチパス構成の仕組みを利用します。現代的なネットワーク環境では、一般に複数の通信経路を並列に使用するマルチパス構成が利用されます(図1)。それぞれのネットワークスイッチは、パケットのヘッダー情報に基づいてパケットを送出するポートを選択するので、TCP通信であれば、セッションごとに異なる経路が用いられます。言い換えると、同一のセッションに伴うパケットは、すべて同じ経路を通ります。ただし、同一のセッションであっても、一般に、行きの経路と戻りの経路は異なります。そのため、行きの経路、戻りの経路、それぞれで独立に障害が発生する可能性があります。
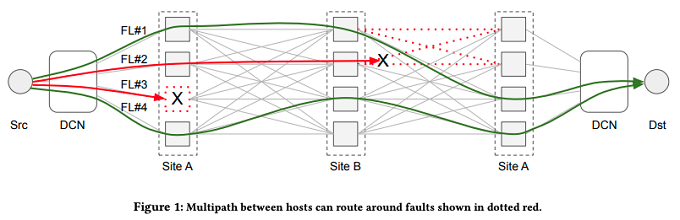
図1 複数経路による通信処理の模式図(論文より抜粋)
図1の例では、4つのセッションによる通信が行われており、その内の2つのセッションに対する経路上で障害が発生しています。この際、それぞれのスイッチのECMPの設定を変更すれば、これらの経路を変更することも可能ですが、サーバー側からスイッチの設定を直接変更するのは少し無理があります。そこで、PRRでは、IPv6のフローラベルを利用します。フローラベルは、通信経路の品質確保や経路の優先選択のために用意されたパケットヘッダーのフィールドです。それぞれのスイッチをフローラベルの値を含めたハッシュ値で経路を選択するように設定しておき、サーバー側では、それぞれのセッションに対して異なるフローラベルを設定します。こうすれば、サーバー側では、特定のセッションに対するフローラベルの値を変更することで、そのセッションで使用する経路が変更できます。
ただし、フローラベルの値と実際に使用される経路の関係は、容易に特定できるものでありません。PRRの目的は、あくまでも一時的な回復処理ですので、サーバー側ではフローラベルの値をランダムに変更して、現在の経路とは異なる経路にランダムに切り替えます。図1のように複数の経路で障害が発生している場合、新しい経路でも通信できない可能性がありますが、このような場合は、フローラベルを再度変更して、さらに新しい経路に切り替えます。図2は、2種類のこのようなパターンを示したもので、左の図では、送信側から受信側のサーバーに至る経路に障害が発生しており、2回の経路切り替えで通信が回復しています。
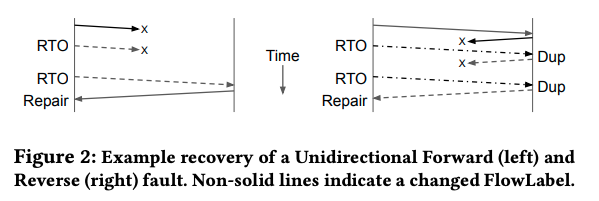
図2 PRRによる障害回復パターンの例(論文より抜粋)
一方、右の図では、受信側のサーバーからの応答パケットの通信経路で障害が発生しています。この場合は、受信側のサーバーで応答パケットに付与するフローラベルを変更する必要があります。これはどのように実現すればよいのでしょうか? ここでは、Packet Duplicationのイベントを利用します。まず、送信側のサーバーは、受信応答(ACK)パケットが戻らないので、経路を切り替えてパケットを再送します。すると、受信側のサーバーでは、同じパケットを2回受信するPacket Duplicationのイベントが発生します。受信側のサーバーは、これをトリガーにしてフローラベルを変更します。図2の例では、こちらも2回の経路切り替えで通信が回復しています。このパターンの場合、本来は送信側での経路変更は不要です。しかしながら、送信側からみた場合、どちら向きの経路に障害が発生しているかは判別できません。そのため、送信側でもパケットを再送するタイミングでフローラベルの変更が行われます。
また、図2にある「RTO(Retransmission Timeout)」は、TCPのプロトコルにおいて、受信応答が戻らないと判断するまでの時間です。この値を短く設定しておけば、より短時間で障害から回復できます。Googleのネットワーク環境でのRTOは、隣接する都市間の通信で数ミリ秒、大陸内での通信で数十ミリ秒、大陸をまたがるグローバルな通信で数百ミリ秒程度に設定されています。また、サーバー側でフローラベルを動的に変更する機能は、Linuxカーネルの機能として実装されたものを利用しています。
今回は、2023年に公開された論文「Improving Network Availability with Protective ReRoute」に基づいて、ネットワーク通信の信頼性を向上するGoogle独自の仕組みであるProtective ReRoute(PRR)について、その役割と基本的な実装内容を説明しました。次回は、シミュレーションによるPRRの動作検証の結果を紹介します。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes

























