
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
今回からは、2023年に公開された論文「Profiling Hyperscale Big Data Processing」に基づいて、Googleの大規模データ処理システムのプロファイリングデータを紹介します。Spanner、BigTable、BigQueryと言った大規模データ処理システムは、さまざまな機能が連携する分散処理システムになっており、システムを構成するどの部分、もしくは、どのような処理に実行時間が割かれているのかを分析したデータになります。今回は、まず、分析対象システムの概要を説明します。
第76回の記事では、今からおよそ20年前となる、2003年ごろのGoogleの検索システムのアーキテクチャーを紹介しました。そこでは、コモディティPCでクラスターを構築して、ソフトウェアで信頼性を確保するという設計方針を説明しました。この考え方は現在でも基本的には変わっておらず、現在のGoogleのシステムの多くは、多数のサーバーが並列に処理を行う大規模分散システムとして設計されています。しかしながら、近年は、すべての処理を汎用的なサーバーで行うのではなく、特定の処理に特化した専用のハードウェアをアクセラレーターとして併用する考え方も取り入れられています。ニューラルネットワークの計算処理に特化したTPUなどは、その代表例と言えるでしょう。
それでは、Spanner、BigTable、BigQueryと言った、Googleを代表する大規模データ処理システムにアクセラレーターを導入するとした場合、どのような処理をアクセラレーターで行うのが効果的でしょうか? ―― この疑問に答えるには、これらのシステムを構成するさまざまなパーツの処理時間を計測する必要があります。冒頭の論文では、将来のアクセラレーター設計の基礎データとするために、これらのシステムの処理時間をいくつかの観点で分析したプロファイリングデータが公開されています。
また、一言でアクセラレーターと言っても、ネットワーク経由で特定の処理を実行するリモートサービスとして実装する、あるいは、サーバー内部に専用チップとして搭載するなど、さまざまな実装方法が考えられます。この論文では、プロファイリングデータに基づいたシミュレーションにより、複数の実装方法による性能向上を比較した結果も紹介されています。
この論文では、Spanner、BigTable、BigQueryの3つのシステムを分析対象としていますが、その理由を次のように説明しています。まず、これらはGoogleのさまざまなシステムの中でも、リソース使用量が大きく、すべてのデータセンターのCPU使用量の10%以上をこれらのシステムが占めています。言い換えれば、これらのシステムのリソース使用量を効率化することは、Googleのデータセンター全体の効率化に寄与することになります。また、これらのシステムは、これまでにさまざまなチューニングや最適化が行われてきています。そのため、さらなる性能向上の手段として、アクセラレーターの適用を検討する自然な対象になります。図1は、それぞれのシステムのアーキテクチャーの概要を示したものですが、それぞれの特徴が次のように説明されています。
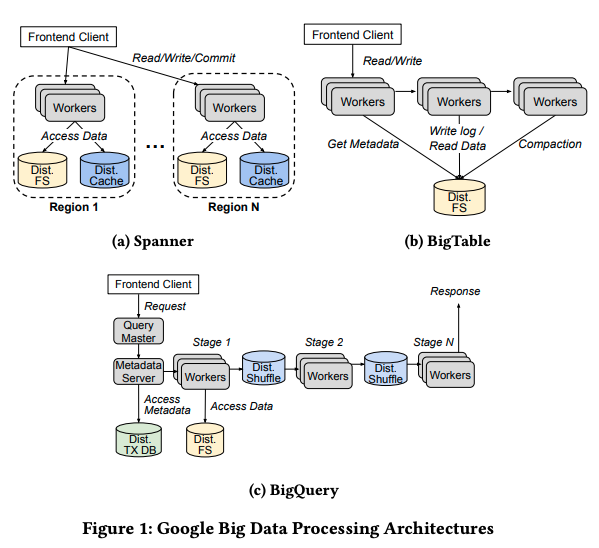
図1 Spanner、BigTable、BigQueryのアーキテクチャー(論文より抜粋)
まず、Spannerは、地理的に分散された同期レプリケーション機能を持ったデータベースです。図1(a)にあるように、複数のリージョンのワーカーは、各リージョンの分散ファイルシステム、および、分散キャッシュに保存されたデータにアクセスします。その上で、各リージョンのワーカーが協調して、リージョン間での強い整合性を持ったトランザクションを実現します。Spannerのデータベースは、ペタバイトクラスのデータを取り扱うスケーラビリティを持ちます。
次に、BigTableは、図1(b)のように、1つのクラスターに閉じて構成されるKey-Valueストアのシステムです。複数のクラスターにデータをレプリケーションすることもできますが、クラスター間のデータには、結果整合性が適用されます。Spannerと同様に、ペタバイトクラスのデータを取り扱うスケーラビリティを持ちます。
そして、BigQueryは、SQLによるデータ分析の機能を提供するマルチテナント型の分散データウェアハウスです。図1(c)に示すように、複数のステージでのデータ処理が行われて、それぞれのステージの間では、シャッフル処理に特化した専用システムが使用されます。1秒間に数十億行のデータを処理することで、大規模データに対する対話的な分析を可能にします。
これらのシステムでは、高速なデータアクセスを実現するために、ハードディスク(HDD)の他に、SSDやサーバーのメモリー(RAM)を用いたキャッシュシステムを使用します。HDD、SDD、RAMの3種類のストレージを使用する割合は、システムごとに異なっており、図2のようにまとめられます。それぞれ、RAMへの保存量に対して、SSDとHDDへの保存量が何倍になっているかを示しています。

図2 システムごとのRAM、SSD、HDDの使用割合(論文より抜粋)
たとえば、Spannerの場合、SSDに保存されるデータはRAMに保存されるデータの8倍、そして、HDDに保存されるデータはRAMに保存されるデータの90倍になります。これらから計算すると、Spannerに保存された全データの約1%にあたる量がRAM上にキャッシュされています。Spannerが扱うデータの総量を考えると、相当な量のデータがRAMに保存されていることが想像できるでしょう。論文では、このバランスをより最適化して、RAMの使用量を削減すれば、コスト削減が図れる可能性がある点も指摘されています。
今回は、2023年に公開された論文「Profiling Hyperscale Big Data Processing」に基づいて、Googleを代表する大規模データ処理システムのプロファイリングデータの役割、そして、この論文が分析対象とするシステムの概要を説明しました。次回からは、実際のプロファイリングデータを紹介していきます。
Disclaimer:この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes

























