
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
連載の2回目では「データレイクをクラウド上で構築・運用するメリット」とはどんなものなのかを説明します。
まず、前回の復習です。前回はクラウドが付かない「データレイクとは何か」を紹介しました。
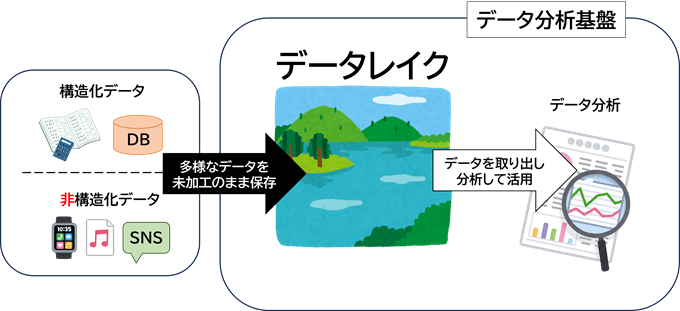
データレイクとは、データ分析基盤の構成要素の一つで、データ分析の基となるデータを未加工のまま保存するリポジトリ(保管場所)です。
様々なソースから収集した多様なデータをデータレイクに保存しておけば、
取り出して、データ分析に活用することができます。
それでは、データレイクを効率的に構築・運用するにはどんなことに注意する必要があるのでしょうか? データカタログの整備やセキュリティガバナンスなど、注意点は多数ありますが、下記の3つが特に重要です。
1)大容量で安価なストレージ
2)需要の増減に対応できる弾力性
3)ビジネスの成長に追いつけるスケーラビリティ
データレイクに保存するデータは、商品化カタログや顧客情報、センサーデータ、ログデータ、SNSの投稿データなど、多種多様です。これらのデータを長期間にわたって効率的に保存するためには、大容量で安価なストレージが必要不可欠です。
また、前回に説明した内容ですが、データレイクをデータスワンプ(=データを取り出すことができない沼)にさせないためには、定期的なデータクレンジングが必要です。その際はデータレイク内に「クレンジング前のオリジナルデータ」と「クレンジング後のキレイにしたデータ」の両方を持つことになるので、必要なストレージ容量がさらに増えます。それに加えてデータのバックアップや冗長化も考慮すると、データレイクにはペタバイト級のストレージ容量が必要になってきます。
データレイクに保存するデータの量やアクセス頻度は常に一定ではなく、ビジネスの成長や季節的な要因、キャンペーンの実施などにより大きく変動します。そのため、需要が急増した際にはリソースを迅速に増やし、逆に需要が減少した際にはリソースを減らす弾力性がデータレイクには必要です。適切な弾力性を備えておけば、需要が大きく増減しても常に最適なパフォーマンスを提供しつつ、コスト効率を保つことが可能になります。
ビジネスの成長に伴い、データ分析のニーズも変化します。
例えば「先月実施したインフルエンサーマーケティングで、どの口コミが効果的だったのか分析を行いたい」といった場合、従来のデータソースにプラスして新たにSNSの投稿データも加えなければいけません。そのような新しいデータソースの追加に柔軟に対応できるスケーラビリティが、データレイクには必要です。
また、データソースの追加で扱うデータ量が増えると、各種データ処理のパフォーマンスが低下する可能性があります。データ量が増加してもパフォーマンスが低下しないように、ストレージI/Oや計算リソースの拡張も容易にできるアーキテクチャをデータレイクは備えておかなければなりません。
この重要な3要素を安価に実現するためには、オンプレミス環境ではなくクラウドサービスの利用が最適です。
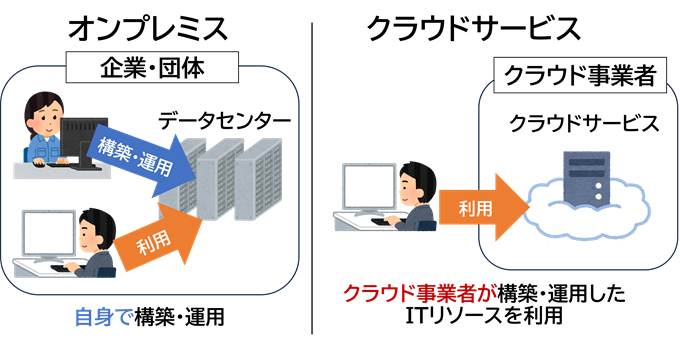
それでは3要素について、オンプレミス環境で構築・運用した場合の課題と、クラウドでの課題の解決方法をそれぞれ説明します。
オンプレミス環境でペタバイト級の大容量のストレージを構築・運用する場合、初期投資が非常に高額になります。
大容量のデータ処理に耐えられる高性能なストレージデバイスやサーバーを購入する必要がありますし、設置や設定、保守管理にも専門的な技術を持ったエンジニアが必要です。また、データ量が増加して限界に達するたびに新たなハードウェアを追加する必要があり、その都度コストが発生します。さらに、オンプレミス環境では、ストレージの管理やバックアップ、データの冗長性確保なども自身で行わなければならず、運用コストも高くなります。
これに対してクラウドサービスは、ストレージを利用した分だけの料金を支払う従量課金モデルになっています。クラウド事業者は、膨大なデータを格納するためのインフラを既に整備しており初期投資が不要ですし、データ量が増加しても追加のハードウェア投資も不要です。また、ストレージ管理やバックアップなどの運用管理も、クラウド事業者が行ってくれます。このため、初期投資を抑えつつ、必要に応じて柔軟に容量を拡張できる、コスト効率が高い大容量のストレージを容易に実現できます。
オンプレミス環境では、需要の変動に迅速に対応することが困難です。データ処理の需要が増加した場合、オンプレミス環境では追加のハードウェアを購入して設置するまでに時間がかかるため、リソースが不足してもすぐには対応できません。また、逆に需要が減少した場合は、既に購入したハードウェアが無駄になってしまい、コスト効率が悪化します。
これに対してクラウドサービスでは、需要の変動に応じてリソースを動的に調整することができます。例えば、データ処理のピーク時には一時的にリソースを増やし、需要が落ち着いたら増やしたリソースを減らすことが可能です。これにより、無駄なコストを削減しつつ、必要な時に必要なだけのリソースを確保できます。さらに、クラウド事業者は自動スケーリング機能を提供しています。これを利用すれば、ユーザーは手動でのリソース調整を行わずに済むため、運用の手間も大幅に軽減できます。
オンプレミス環境の場合、ビジネスの成長スピードに追いつくことが困難です。ビジネスの成長に伴う新しいデータソースの追加やデータ量の急増でストレージの容量や性能が限界に達してしまった場合、オンプレミス環境では自身で追加のハードウェアを購入し、設置・設定する必要があります。これには時間とコストがかかり、すぐには対応できません。
これに対してクラウドサービスでは、ビジネスの成長に合わせてのスケールアップが容易です。クラウドサービスでは、利用者側で新たな設備投資をすることなく単に追加のコストを支払うだけで、新しいデータソースの追加やデータ量が急増に迅速に対応できます。例えば、新しいマーケットに進出する際や、新製品のローンチ時に大量のデータが発生しても、クラウドサービスならば迅速に対応可能です。
また、オンプレミス環境では、最新の技術やツールを導入する際にも、既存のインフラとの互換性や設定の問題が発生することがあり、迅速な対応が難しいです。一方、クラウドサービスでは、最新の技術やツールを簡単に導入できるため、企業はデータ駆動型の意思決定を迅速に行い、競争力を維持することができます。
これらのメリットにより、クラウドでのデータレイク構築・運用は多くの企業にとって非常に魅力的な選択肢となっています。
今回は「データレイクをクラウド上で構築・運用するメリット」を紹介しました。
次回は「クラウドデータレイクサービスとその事例」を紹介する予定です。
参考文献:Rukmani Gopalan (著), 丸本 健二郎 (監修), 長尾 高弘 (翻訳)(2024)
『クラウドデータレイク ―無限の可能性があるデータを無駄なく活かすアーキテクチャ設計ガイド』
オライリー・ジャパン
| ~「なんとなく知っている」を「はっきりわかる」へ~ クラウド概要 様々なビジネスシーンにおいて利用が拡大しているクラウドの基礎知識を習得します。 本コースでは、クラウドコンピューティングとは何か、やメリット/デメリット、どのようなサービスが利用できるか、などを紹介します。また、代表的なパブリッククラウドサービスの特徴を事例を交えながら活用方法を紹介します。 コースの詳細・開催スケジュール |
| ~統計基礎からデータ分析の考え方まで~ ゼロから始めるデータサイエンス ~DS検定リテラシーレベル対応講座~ インターネットやビッグデータの広がりと共に、多種多様なデータが収集され蓄積されるようになりました。これからの時代を生き抜くためには、このたくさんのデータを正しく集め、正しく分析し、正しく利用することが求められます。 本コースでは、データサイエンティストに求められる基礎スキルを、2日間の講座で分かりやすく丁寧に解説します。統計の基礎知識だけでなく、データを収集するときの注意点や分析のポイント、そしてその後の利用や扱い方について、具体的で実践的な内容を扱います。データサイエンティストとして活躍するための基礎力はもちろん、今の時代を生きるすべての人に必要な「データを扱う力」を養う事を身に着ける手助けになります。「与えられた情報を見るだけ」だった状態から、「その情報の裏に潜む何か」を見つけられるようになりましょう! また本コースのカリキュラムは、データサイエンティスト検定リテラシーレベルのシラバスに沿った構成となっているため、試験を受験予定の方にもおすすめのコースです。(シラバスver5対応) ※本コースはデータサイエンス協会の監修済みコースです。 コースの詳細・開催スケジュール |
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes

























