
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
これから学ぶ人も、資格取得を目指す人も、最適なカリキュラムを選べます。
CTC 教育サービス
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes
本コラムでは、データ分析や機械学習の実現するためのデータ基盤として注目されている「クラウドデータレイク」の魅力を数回にわたって紹介します。第1回目では、クラウドが付かない「データレイク(Data Lake)」とはどんなものなのかを説明します。
まず、データレイクの活用例であるBI (ビジネス・インテリジェンス)を見ていきましょう。

DX(デジタル・トランスフォーメーション)の事例として、BIが注目されています。BIとは、企業が蓄積している様々なデータを分析・活用し、経営や各部門の意思決定に役立てる手法です。
例えば、作業服大手のワークマンでは、2012年からExcel 使ったデータ活用を社員一人一人が実施し、販売実績や業務効率の向上に役立てています。その結果、14期連続で売上高が過去最高を更新するという大躍進をとげました。まさに「BIを活用したデータドリブンな経営戦略」の成功例です。
そして、効果的なBIを実現するためには適切なデータ分析基盤が必要です。

データ分析基盤は、3つの要素で構成されています。
それぞれの役割を説明します。
データレイクでは、様々なソースから収集した多様なデータを"未加工のまま"保存します。雨や川の水を貯めておく湖のように、様々な水源(データソース)から流れ込んでくる多様なデータを蓄積する「データの貯蔵庫(湖)」がデータレイクです。データウェアハウスでは、データレイクの未加工のデータを、分析できるように加工(=正規化)し保存します。ウェアハウスとは倉庫のことです。素材や部品を加工し箱につめ倉庫内の棚に分類して格納しておくように、データを加工して分析しやすいように正規化し保存しておくのがデータウェアハウスの役割です。
最後のデータマートでは、データウェアハウスのデータを特定の目的や用途ごとに整理し、分析しやすいように個別に分けて保存します。ここで言うマートとは、八百屋や魚屋といったニーズごとの小売店のことです。料理を作るために巨大な倉庫に赴き、目的の食材をイチから探し出すのは大変です。なので、キャベツが欲しいなら八百屋に行く、魚屋に行けば三枚おろしのサンマが手に入る、といった具合に小売店が重宝されます。それと同じように、データマートで目的や用途ごとにデータを事前に整理・加工し可視化しておくことで、データ分析を素早く行えるようになります。
データ分析基盤でデータレイクが必要とされる理由は2つあります。
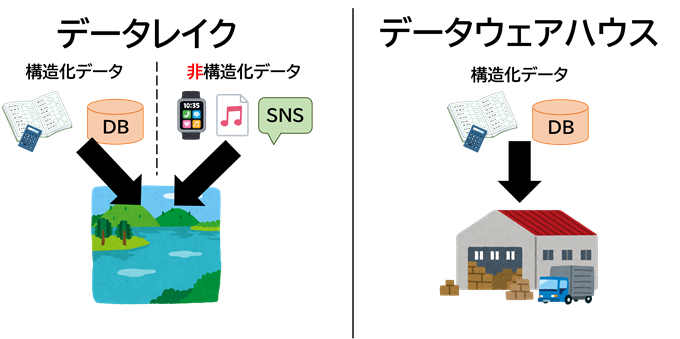
データには、構造化データと非構造化データの2種類があります。

データレイクでは、構造化データと非構造化データの両方を一元的に保存します。データウェアハウスでは、基本的に分析用に
整理された構造化データのみ保存し、多様なデータは保存できません。
 「ビッグデータ」という言葉が登場して10年以上たちますが、IoT機器の普及やソーシャルメディアの発展にともない、データ分析
の対象となるデータは、ますます多種多様になっています。
「ビッグデータ」という言葉が登場して10年以上たちますが、IoT機器の普及やソーシャルメディアの発展にともない、データ分析
の対象となるデータは、ますます多種多様になっています。
例えば、スマートウォッチの活動データを基に運動量や睡眠時間を分析したり、Instagram のトレンドやいいね数を指標にエン
ゲージメント率の算出したり等、データソースの多様化やその分析の需要は、拡大し続けています。
それらの必要とされるあらゆる多様なデータを、ファイル形式やフォーマットを問わず、一元的に格納・蓄積するのがデータレイクです。

データレイクでは、多様なデータソースから集めた膨大な生データを加工せず、「オリジナルな形式のまま保存」しています。
そのため、柔軟性が高くさまざまな分析や処理にデータを利用できます。
データ分析を魚の調理で例えると、
という違いがあります。
生魚のまま保存しておけば、新たなニーズ(例:刺身を食べたい)や新しい手法(例:真空調理)が登場した際に、慌てることなく対応可能です。
それと同じように、生データをデータレイクに保存しておけば、新たなデータ分析ニーズやデータ分析手法にも柔軟に対応でき ます。
最後にデータレイクを扱う際の注意点を紹介します。
データレイクの対義語に「データスワンプ(Data Swamp、スワンプ=沼)」があります。
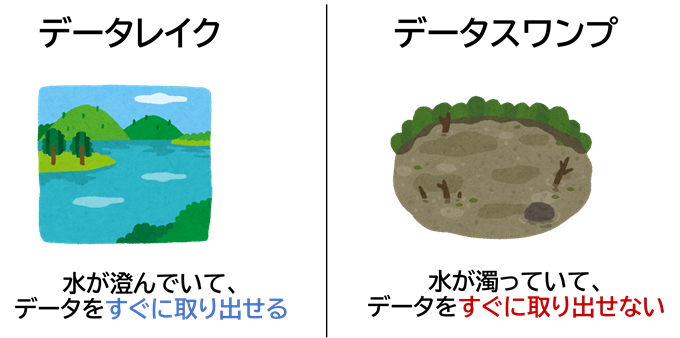
前述したように、データレイクには多様な生データをそのまま保存できます。ですが、「とりあえず何でも入れておこう!」と適切な管理手法などを一切考慮せずに単にデータを保存しているだけでは、ただデータが入っているだけで取り出すことができない、価値のない「沼」になってしまいます。
データレイクを沼化させないためには、以下の2点の維持管理が必要です。
データレイクに保存する際に「それがどんなデータなのか?(=メタデータ)」も一緒に保存してください。
また、データソースや粒度、種別、形式などの属性もメタデータとして記録して適切なタグを付けて整理しておきます。
そして、メタデータを管理する「データカタログ」を導入し、
等、データを適切に整理・分類し、データをすぐに取り出せる状態を維持してください。
データレイクを定期的に掃除して、ゴミや泥を定期的に取り除くのがデータクレンジングです。
具体的には、
等を定期的に実施し、保存データの品質・信頼性を落とすことがないように気を付けましょう。
「クラウドデータレイク」を理解する前提として、まずはクラウドが付かない「データレイク」を紹介しました。 次回は「データレイクをクラウド上で構築・運用する必要性」を解説する予定です。
参考文献:Rukmani Gopalan (著), 丸本 健二郎 (監修), 長尾 高弘 (翻訳)(2024)
『クラウドデータレイク ―無限の可能性があるデータを無駄なく活かすアーキテクチャ設計ガイド』
オライリー・ジャパン
| ~「なんとなく知っている」を「はっきりわかる」へ~ クラウド概要 様々なビジネスシーンにおいて利用が拡大しているクラウドの基礎知識を習得します。 本コースでは、クラウドコンピューティングとは何か、やメリット/デメリット、どのようなサービスが利用できるか、などを紹介します。また、代表的なパブリッククラウドサービスの特徴を事例を交えながら活用方法を紹介します。 コースの詳細・開催スケジュール |
| ~統計基礎からデータ分析の考え方まで~ ゼロから始めるデータサイエンス ~DS検定リテラシーレベル対応講座~ インターネットやビッグデータの広がりと共に、多種多様なデータが収集され蓄積されるようになりました。これからの時代を生き抜くためには、このたくさんのデータを正しく集め、正しく分析し、正しく利用することが求められます。 本コースでは、データサイエンティストに求められる基礎スキルを、2日間の講座で分かりやすく丁寧に解説します。統計の基礎知識だけでなく、データを収集するときの注意点や分析のポイント、そしてその後の利用や扱い方について、具体的で実践的な内容を扱います。データサイエンティストとして活躍するための基礎力はもちろん、今の時代を生きるすべての人に必要な「データを扱う力」を養う事を身に着ける手助けになります。「与えられた情報を見るだけ」だった状態から、「その情報の裏に潜む何か」を見つけられるようになりましょう! また本コースのカリキュラムは、データサイエンティスト検定リテラシーレベルのシラバスに沿った構成となっているため、試験を受験予定の方にもおすすめのコースです。(シラバスver5対応) ※本コースはデータサイエンス協会の監修済みコースです。 コースの詳細・開催スケジュール |
[IT研修]注目キーワード Python Power Platform 最新技術動向 生成AI Docker Kubernetes

























